
大模型之家讯 今日,商汤科技与上海人工智能实验室联合香港中文大学和复旦大学正式推出书生·浦语大模型(InternLM)200亿参数版本InternLM-20B,并在阿里云魔搭社区(ModelScope)开源首发。
同时,书生·浦语面向大模型研发与应用的全链条工具链全线升级,与InternLM-20B一同继续全面开放,向企业和开发者提供免费商用授权。
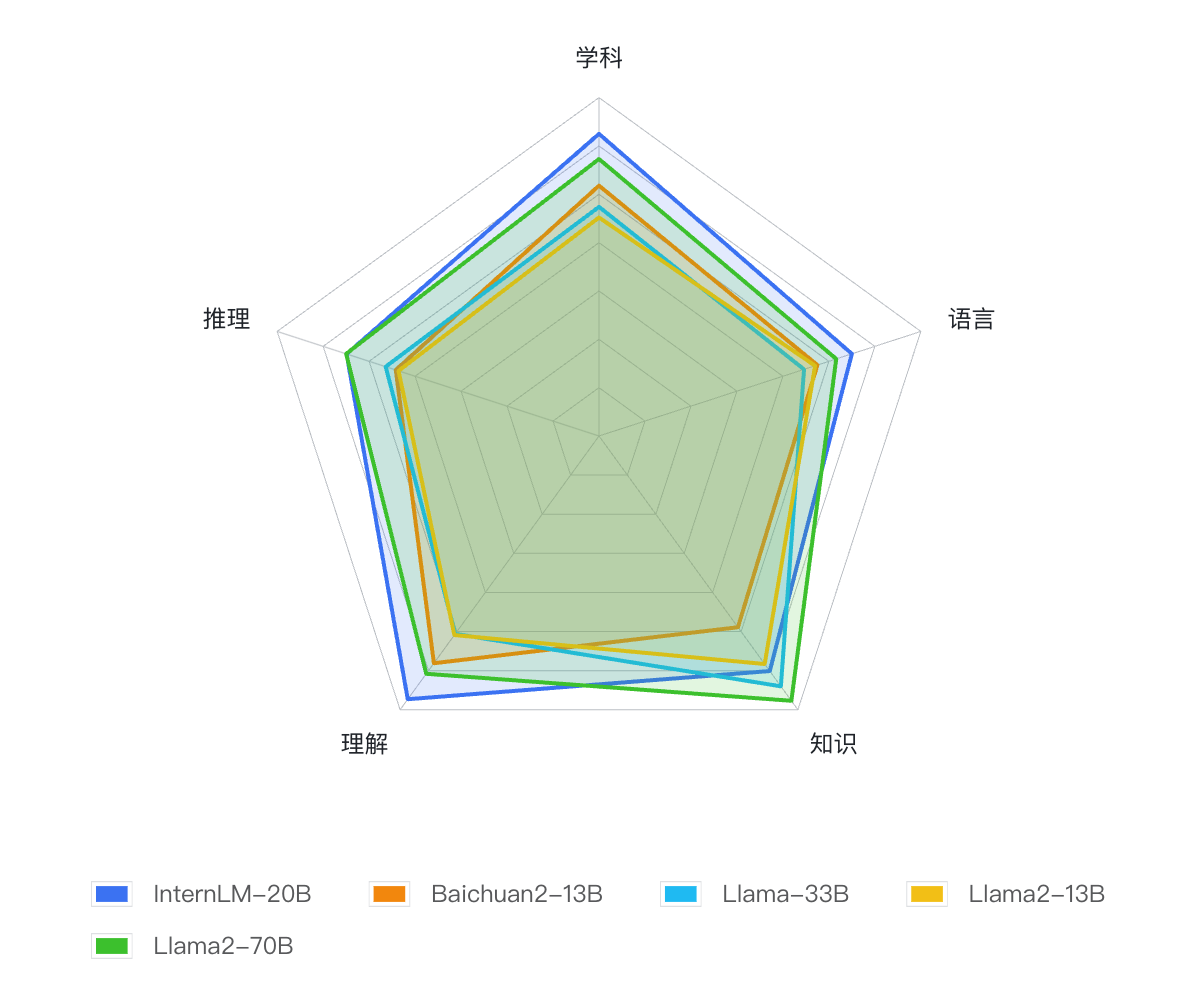
自今年6月首次发布以来,书生·浦语已经历多轮升级,在开源社区和产业界产生了广泛影响。InternLM-20B模型性能先进且应用便捷,以不足三分之一的参数量,达到了当前被视为开源模型标杆的Llama2-70B的能力水平。
代码库链接:https://github.com/InternLM/InternLM
魔搭社区链接:https://modelscope.cn/organization/Shanghai_AI_Laboratory


书生·浦语“增强版”:增的不只是量
相比于国内社区之前陆续开源的7B和13B规格的模型,20B量级模型具备更为强大的综合能力,在复杂推理和反思能力上尤为突出,因此对于实际应用能够带来更有力的性能支持。
另一方面,20B量级模型可以在单卡上进行推理,经过低比特量化后,可以运行在单块消费级GPU上,给实际使用带来很大的便利。
InternLM-20B是基于2.3T Tokens预训练语料从头训练的中量级语言大模型。相较于InternLM-7B,训练语料经过了更高水平的多层次清洗,补充了高知识密度和用于强化理解及推理能力的训练数据。
在理解能力、推理能力、数学能力、编程能力等考验语言模型技术水平的方面,InternLM-20B与此前已开源模型相比,性能显著增强:优异的综合性能,通过更高水平的数据清洗和高知识密度的数据补充,以及更优的模型架构设计和训练,显著提升了模型的理解、推理、数学与编程能力。
InternLM-20B全面领先量级相近的开源模型,使之以不足三分之一的参数量,评测成绩达到了被视为开源模型的标杆Llama2-70B水平。
- 拥有强大的工具调用能力,实现大模型与现实场景的有效连接,并具备代码解释和反思修正能力,为智能体(Agent)的构建提供了良好的技术基础;
- 支持更长语境,支持长度达16K的语境窗口,更有效地支撑长文理解、长文生成和超长对话,长语境同时成为支撑在InternLM-20B之上打造智能体(Agent)的关键技术基础;
- 具备更安全的价值对齐,书生·浦语团队对InternLM-20B进行了基于SFT(监督微调)和RLHF(基于人类反馈的强化学习方式)两阶段价值对齐以及专家红队的对抗训练,当面对带有偏见的提问时,它能够给出正确引导。
全链条工具体系再巩固:各环节全面升级
今年7月,商汤科技与上海AI实验室联合发布书生·浦语的同时,在业内率先开源了覆盖数据、预训练、微调、部署和评测的全链条工具体系。
历经数月升级,书生·浦语全链条开源工具体系巩固升级,并向全社会提供免费商用。

数据-OpenDataLab开源“书生·万卷”预训练语料
书生·万卷是开源的多模态语料库,包含文本数据集、图文数据集、视频数据集三部分,数据总量超过2TB。
目前,书生·万卷1.0已被应用于书生·多模态、书生·浦语的训练,为模型性能提升起到重要作用。
预训练-InternLM高效预训练框架
除了大模型外,InternLM仓库也开源了预训练框架InternLM-Train。深度整合了Transformer模型算子,使训练效率得到提升,并提出了独特的Hybrid Zero技术,使训练过程中的通信效率显著提升,实现了高效率千卡并行,训练性能达行业领先水平。
微调-InternLM全参数微调、XTuner轻量级微调
InternLM支持对模型进行全参数微调,支持丰富的下游应用。同时,低成本大模型微调工具箱XTuner也在近期开源,支持多种大模型及LoRA、QLoRA等微调算法。
通过XTuner,最低仅需 8GB 显存即可对7B模型进行低成本微调,在24G显存的消费级显卡上就能完成20B模型的微调。
部署-LMDeploy支持十亿到千亿参数语言模型的高效推理
LMDeploy涵盖了大模型的全套轻量化、推理部署和服务解决方案,支持了从十亿到千亿级参数的高效模型推理,在吞吐量等性能上超过FasterTransformer、vLLM和Deepspeed等社区主流开源项目。
评测-OpenCompass一站式、全方位大模型评测平台
OpenCompass大模型评测平台构建了包含学科、语言、知识、理解、推理五大维度的评测体系,支持超过50个评测数据集和30万道评测题目,支持零样本、小样本及思维链评测,是目前最全面的开源评测平台。
自7月发布以来,受到学术界和产业界广泛关注,目前已为阿里巴巴、腾讯、清华大学等数十所企业及科研机构广泛应用于大模型研发。
应用-Lagent轻量灵活的智能体框架
书生·浦语团队同时开源了智能体框架,支持用户快速将一个大语言模型转变为多种类型的智能体,并提供典型工具为大语言模型赋能。
Lagent集合了ReAct、AutoGPT 及ReWoo等多种类型的智能体能力,支持智能体调用大语言模型进行规划推理和工具调用,并可在执行中及时进行反思和自我修正。
基于书生·浦语大模型,目前已经发展出更丰富的下游应用,将于近期陆续向学术及产业界分享。
面向大模型掀起的新一轮创新浪潮,商汤科技坚持原创技术研究,通过前瞻性打造新型人工智能基础设施,建立大模型及研发体系,持续推动AI创新和落地,引领人工智能进入工业化发展阶段,同时赋能整个AI社区生态的繁荣发展。
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/956