
大模型之家讯 近日,昆仑万维2050研究院颜水成团队与北京大学袁粒团队联合推出了新一代的混合专家模型框架MoE++,该框架相较于传统的MoE(混合专家模型)在推理速度和性能上都有显著提升。MoE++引入了“零计算量专家”的创新设计,能够有效降低计算成本,同时提升复杂任务处理的能力,使其更易于在大规模语言模型(LLMs)中部署。
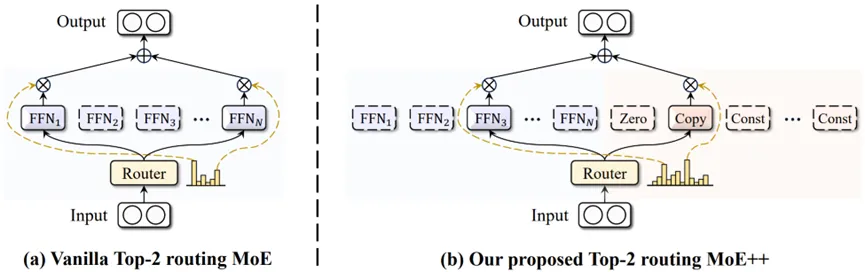

MoE++作为一个通用框架,能无缝集成至任何现有的MoE模型中,尤其在三个关键方面表现突出:(1) 通过允许每个Token选择可变数量的专家,甚至完全跳过当前MoE层,MoE++实现了显著的计算成本降低;(2) 减少简单Token使用的专家数量,使复杂Token得到更多专家资源,从而释放更大的性能潜力;(3) “零计算量专家”占用极小的参数量,使得在每个GPU上可以同时部署所有的零计算量专家,避免了专家负载不均的问题。
实验数据表明,MoE++在0.6B到7B参数规模的模型上实现了1.1到2.1倍的专家吞吐速度,同时在性能上全面超越传统的MoE模型。这一模型现已开源,论文和相关代码可在Arxiv和GitHub上获取。
MoE++框架的发布为大规模语言模型的发展提供了新的技术路径,将进一步推动自然语言处理和AI模型的创新发展。
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/7661