


图源:商汤秒画
上月,Open AI发布了最新版本的GPT-4V使用户能够指示GPT-4分析用户提供的图像输入最新功能,而这一消息引发行业关注,将其他模式(如图像输入)纳入大型语言模型(LLM)被视为人工智能研究和开发的关键前沿,多模式LLM提供了扩大纯语言系统影响的可能性。
从去年年底发布的人工智能聊天机器人ChatGPT,到目前的GPT-4V,Open AI在大型多模态模型 (LMM) 扩展了具有多感官技能(如视觉理解)的大型语言模型 (LLM),实现了更强的通用智能。
在GPT-4V发布不久后,微软针对GPT-4V给出了166页超详细的使用指南,从简单的输入模式到视觉语言能力、与人类交互提示,再到时间视频理解、抽象视觉推理和智商情商测试等,GPT-4V不仅能覆盖日常生活中的交互体验,甚至能够实现在工业、医疗等领域的专业诊断评估等。

图源:微软(网络翻译仅供参考)
目前,GPT-4V在处理任意交错多模态输入方面前所未有的能力及其功能的通用性共同使 GPT-4V成为一个强大的多模态通才系统。此外,GPT-4V理解在输入图像上绘制的视觉标记的独特能力可以产生新的人机交互方法,例如视觉参考提示。
值得肯定的是,GPT-4V的初步探索有可能激发未来对下一代多模态任务公式的研究,利用和增强LMM解决现实问题的新方法,并更好地了解多模态基础模型,也更成为计算机视觉发展方向的新探索。
大模型赋能计算机视觉新发展
或许谈到多模态能力,很多人并不陌生,在国内有不少大模型在推出时就已经拥有多模态能力,能够进行图像识别与生成,但不得不承认的是,相比于LLM(大型语言模型),LMM(大型多模态模型)的发展还有很多漏洞待解决。
此前,大模型之家就体验过多家拥有多模态能力的大模型,以基于AI框架昇思MindSpore“紫东太初”2.0版本大模型平台、讯飞星火为例,在分析、推理及表达能力方面有待进步。
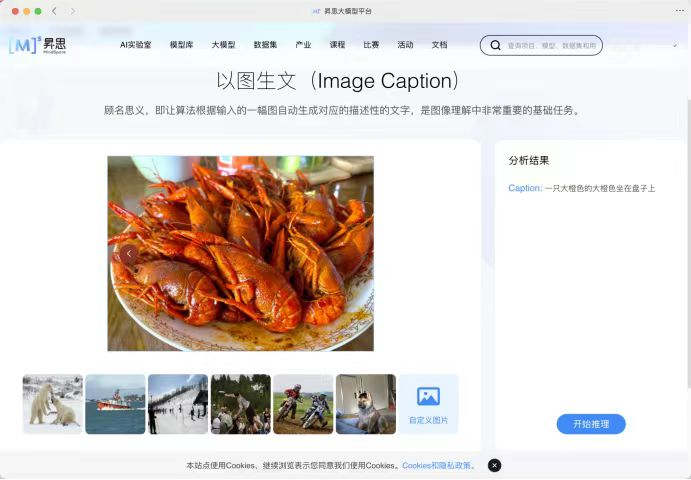
图为:紫东太初
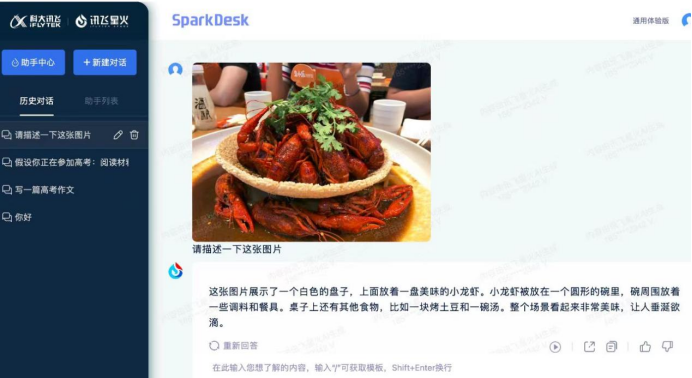
图为:讯飞星火
值得注意的是,在今年4月,Meta提出分割一切的模型SAM(Segment Anything Model),SAM是一个提示型模型,其在1100万张图像上训练了超过10亿个掩码,实现了强大的零样本泛化,有业内人士表示,SAM突破了分割界限,极大地促进了计算机视觉基础模型的发展。
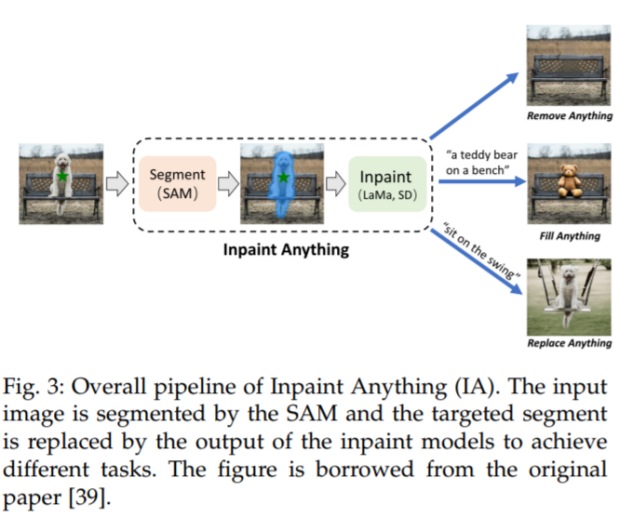
图源:Meta
SAM本身是图像的语义分割,该模型掌握了“对象”的概念,可以为任何图像或视频中的任何对象生成遮罩,即使是它在训练中没有见过的对象。
SAM模型和GPT-4V的出现,能够将大语言模型安装上“眼睛”,也正如Open AI在为GPT-4V生成前所做的部署准备,其中包括Be My Eyes,这是一个为视障用户构建工具的组织,在模型生成前夕,可以想象大模型是一个会说话的“盲人”,但在加入视觉之后,具备多模态能力的大模型能够看得懂图、视频等,这一功能的强大也将人工智能发展推向新的方向。
大模型浪潮下,国内计算机视觉之路
在利用图像输入、识别及推理分析的功能,加入视觉功能后大模型能够实现多领域开花,向“计算机视觉GPT”迈进。

图源:华为
在工业方面,通过将视觉大模型应用到缺陷检测等在制造过程中确保产品质量的重要步骤之中,能够及时检测故障或缺陷并采取适当的措施对于最大限度地降低运营和质量相关成本至关重要,目前国内华为、百度、讯飞等大模型产品均在工业领域有相关成果落地;

图源:商汤科技
在医疗影像诊断方面,结合认知大模型的专业领域知识,加入视觉能力后,不仅能够在各种医学图像中进行分析,还能够快速生成完整的放射学报告,具有作为放射学报告生成的AI助手的潜力,目前商汤基于医学知识和临床数据开发了中文医疗语言大模型“大医”,具有提供导诊、问诊、健康咨询、辅助决策等多场景多轮会话能力。
在自动驾驶方面,可以结合认知大模型在驾驶时的获取的图像信息、动态行驶目标等,给出相应的驾驶决策和驾驶解释,然后大模型将其转化为自动驾驶的语言,通过Drive Prompt和自动驾驶系统做交互,从而实现智能驾驶。

图源:百度
以百度为例,在刚刚召开的2023百度世界大会中,在智驾方面,通过Transformer和BEV等新技术彻底重构自动驾驶技术栈,感知能力获得代际感提升,加速纯视觉方案的成熟和普及。目前,百度Apollo纯视觉高阶智驾方案可应用于高速、城市、泊车等全域场景,将在今年第四季度实现量产,这也是国内首个纯视觉方案在城市场景落地。值得一提的是,去掉激光雷达让整车成本更低,提升了市场竞争力。
大模型之家认为,在大语言模型通用知识的加持下,计算机视觉迎来了更为明确的发展方向,从早期计算机视觉依靠重复记忆进行的实践应用(如人脸识别、物体识别),探索视觉和语言的融合成为大模型和计算机视觉的新方向,从独立发展到相互融合,人工智能也在不断探索和人更为相近的感官能力,能更好地捕捉图像中的细节和特征,大模型的准确性得以提高,可以适应更多的场景和数据分布,依托大模型的能写会道,融合视觉能力,成为更为智能的化身。
当然,科技的发展必定会受到多方面因素的限制。大模型需要更多的计算资源和时间进行训练,这可能限制了其可扩展性和实时性,庞大的训练数据必定会受到算力的限制,特别是高性能的GPU、高速的内存和存储,以及分布式训练技术,而当下全球高性能的GPU市场中英伟达占据近90%份额,我国想要在这场AI竞争中占得高地,推动中国人工智能算力的高质量发展成为当务之急。
总的来说,大模型融合视觉能力后具有很多优势,但现阶段也存在一些发展限制。随着深度学习和计算资源的不断发展,我们可以期待更先进的大模型和相关技术的出现,进一步推动计算机视觉在高分辨率图像任务中的应用和突破。
原创文章,作者:赵小满,如若转载,请注明出处:http://damoai.com.cn/archives/1497