
大模型之家讯 7月28日晚,智谱宣布推出其最新一代通用基础模型 GLM-4.5。该模型已在 Hugging Face 与 ModelScope 上开源,权重遵循 MIT License。这是智谱在大模型智能体方向的一次系统性突破,目标直指推理能力、代码能力与智能体融合能力三者兼备的开源 SOTA。


融合推理、编码与智能体:国产开源模型首次跻身前三
GLM-4.5 是智谱首次实现推理、编码与智能体能力在单一模型架构中的原生融合,面向多模态协同和复杂任务需求进行了深度优化。根据官方公布的数据,在 MMLU Pro、AIME24、MATH 500、GPQA、LiveCodeBench、Terminal-Bench 等12个国际评测基准上,GLM-4.5 平均得分位列全球第三,成为国产模型中的最高分,也是目前开源模型中的领先者。
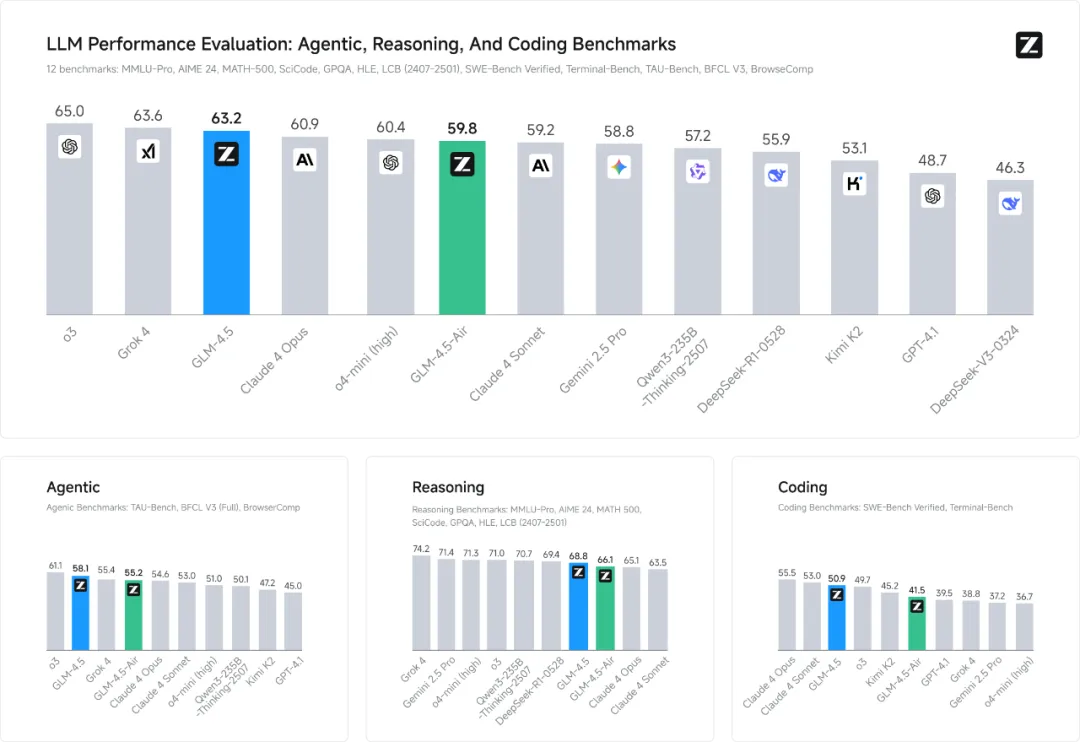
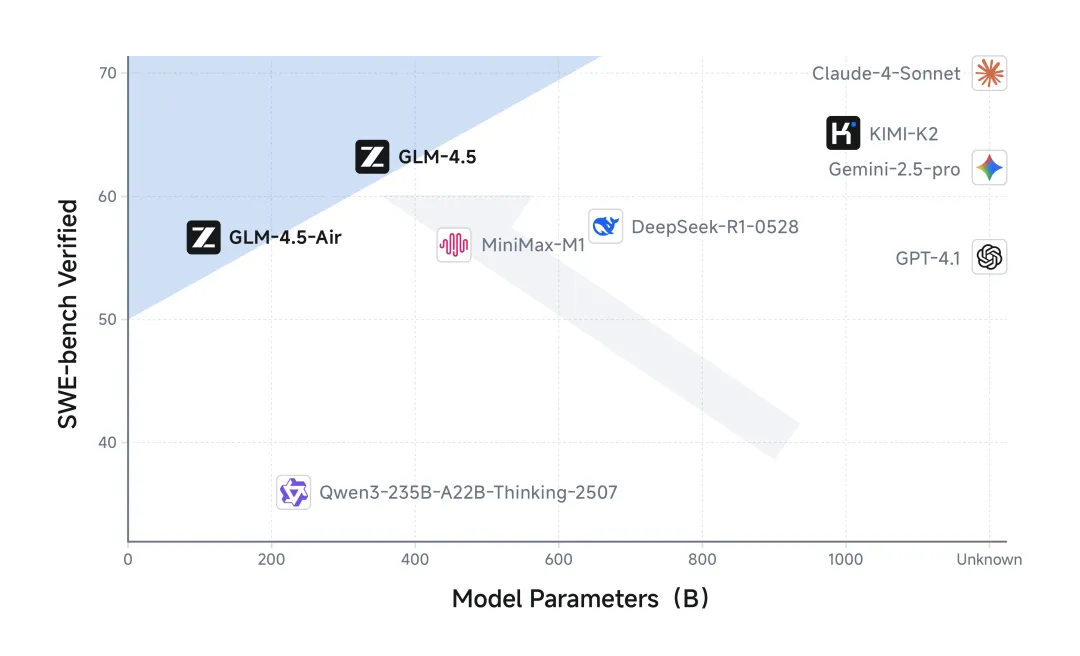
值得注意的是,GLM-4.5 系列采用混合专家(Mixture-of-Experts, MoE)架构,包含两个主力版本:参数总量为 3550 亿、激活参数为 320 亿的 GLM-4.5 以及参数总量 1060 亿、激活参数为 120 亿的 GLM-4.5-Air。在相似规模下,其性能/参数比达到 SWE-Bench Verified 榜单的帕累托前沿,显示出极高的参数效率。
训练过程中,GLM-4.5 先在15万亿token的通用数据上进行预训练,再在8万亿token的专业数据(覆盖代码、推理、智能体任务)上精调,最后通过强化学习进一步提升任务完成度和推理稳定性。智谱方面表示,将在后续技术报告中公开更多训练细节。
真实智能体场景下性能验证,国产开源模型具备“平替”能力
在真实的Agent Coding场景下,GLM-4.5 也进行了交互式对比测试,覆盖前后端开发、代码工具调用等52个任务,与Claude-4-Sonnet、Kimi-K2、Qwen3-Coder等模型进行多轮交互对比。结果显示,GLM-4.5 在任务完成率、工具调用成功率等关键指标上表现优异,在多个场景下已具备对Claude-4-Sonnet的可替代性。为确保测试的透明可复现性,智谱公布了全部测试题目及交互轨迹(https://huggingface.co/datasets/zai-org/CC-Bench-trajectories)。

此外,在模型原生智能体能力方面,GLM-4.5 可完成全栈式开发任务,如模拟“谷歌搜索”“B站”“微博”等完整网页产品,也支持多模态交互、三维动画制作及PPT自动生成等复杂应用,展示出其跨模态、强执行、低延迟的综合能力。
开放生态持续构建,推动国产AGI基础设施演进
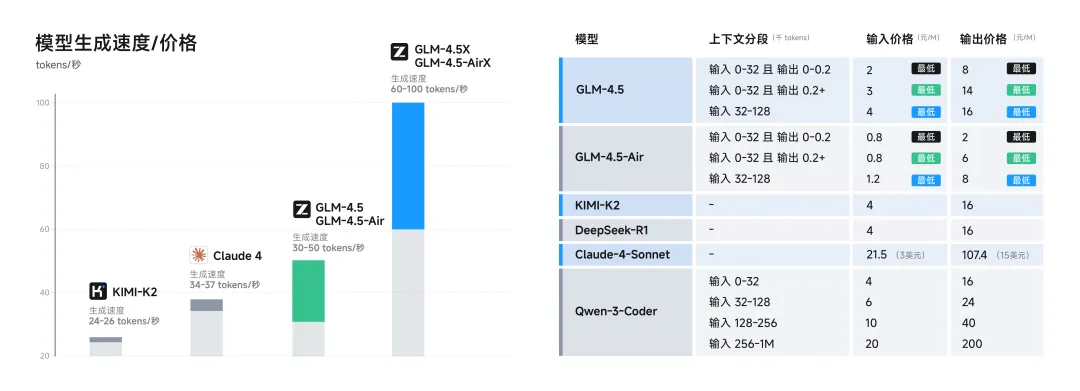
为降低模型的使用门槛,GLM-4.5 已在 BigModel.cn 全面开放API服务,支持与Claude Code框架兼容对接。其API调用定价低至输入0.8元/百万tokens、输出2元/百万tokens,并提供最高达100 tokens/秒的响应速度,适配多并发部署场景。在实际开发体验方面,用户也可通过chatglm.cn与Z.ai体验完整模型能力。
GLM-4.5的发布标志着国产开源大模型在融合通用智能能力、面向真实场景部署方面的一次重要跃迁。智谱同步开源了GLM-4.5的模型权重与代码仓库(https://github.com/zai-org/GLM-4.5),并通过Hugging Face与ModelScope提供模型调用和应用演示平台,进一步降低企业与开发者的接入门槛。
面对推理增强、多模态融合、工具智能体系统的快速发展,GLM-4.5 的推出不仅是一次工程规模的提升,也是在国产AGI技术路径上的关键节点。对于希望在智能体与自动化系统中探索下一阶段机会的行业用户而言,GLM-4.5 将成为一个值得关注的基础能力平台。
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/11803