
大模型之家讯 近日,腾讯优图实验室与复旦大学的研究团队共同提出了一种名为“PixelPonder”的新型多视觉控制解决方案,这一成果在基于扩散的文本到图像生成领域展现出了令人瞩目的潜力。


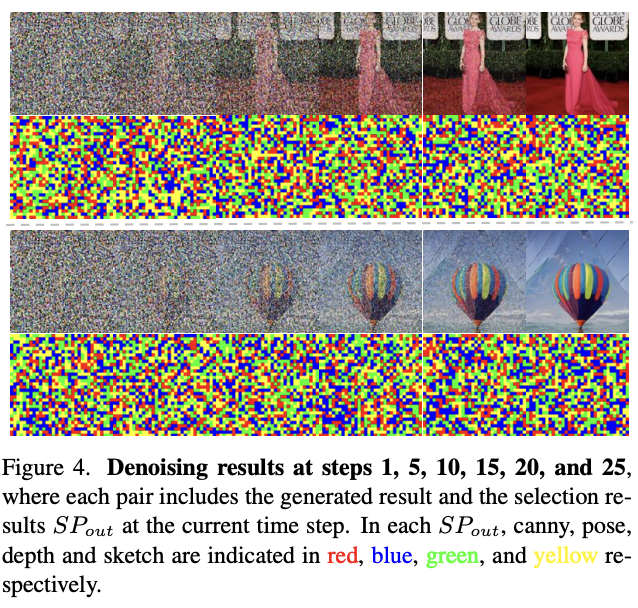
传统的多视觉控制方法在处理多个异构控制信号时,往往难以保持语义保真度与高视觉质量。而PixelPonder通过引入基于补丁的自适应条件适配机制和时间感知的控制注入方案,有效解决了这一难题。
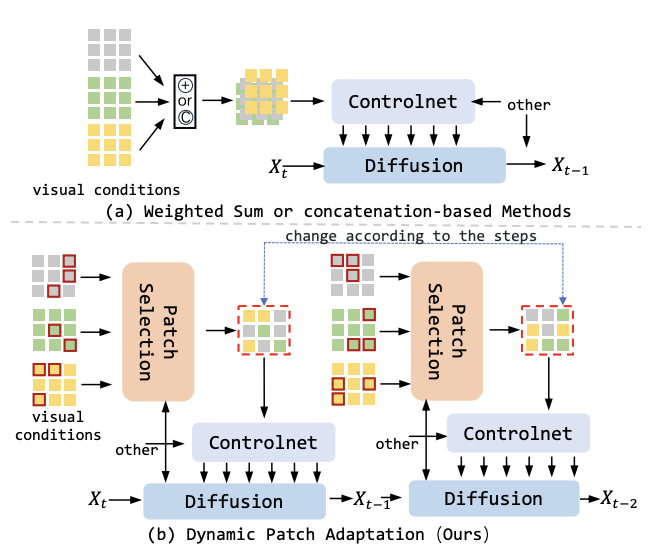
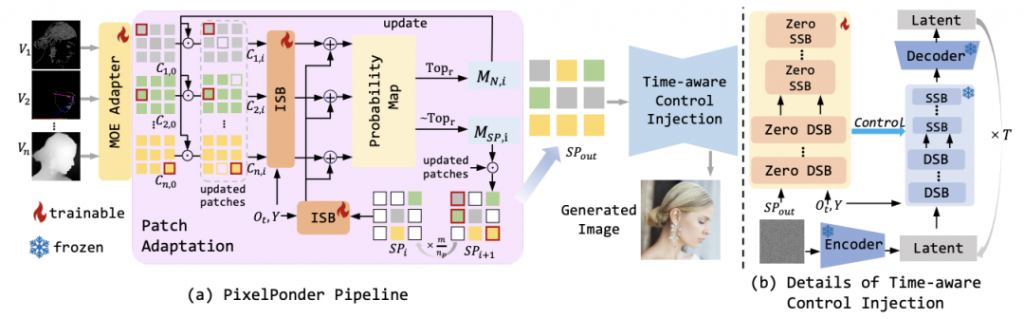
在PixelPonder框架下,研究人员设计了一种独特的Patch Adaption模块(PAM),该模块能够将各类视觉条件在补丁级别上重新组合成统一的视觉条件。与此同时,时间步意识控制注入方案则确保了去噪阶段中条件影响的协调,进一步提升了图像生成的质量。
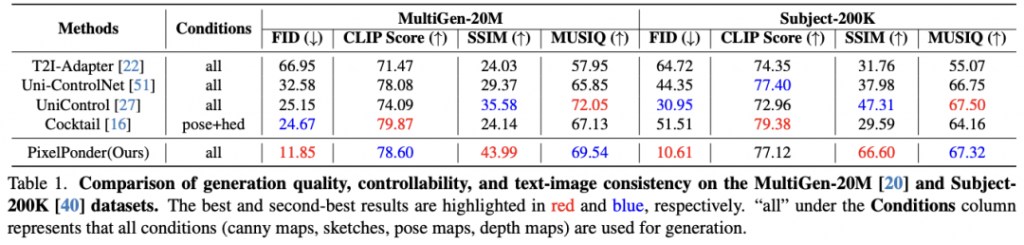
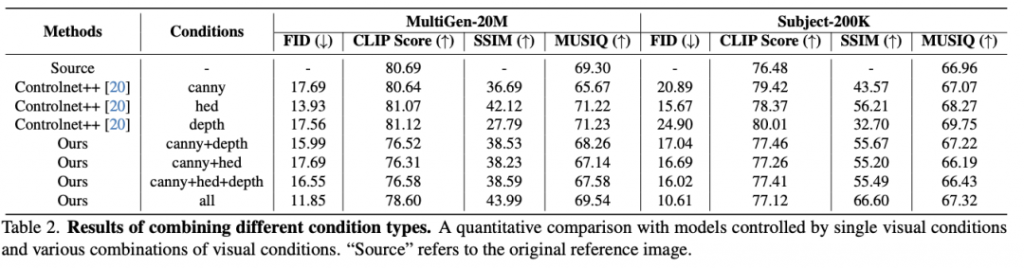
实验结果显示,PixelPonder在不同基准数据集上均超越了现有方法,不仅在空间对齐精度上表现出显著提升,而且保持了高文本语义一致性。尤其在视觉控制和文本控制的trade-off方面,PixelPonder表现出了卓越的平衡能力。

总结来说,PixelPonder的诞生标志着基于扩散的图像生成领域迈向了一个新纪元。通过这一技术,用户将能够更加精确地描绘对象的不同方面,从而实现他们的创作愿望。
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/10632