


在 8 月智谱发布的音视频通话功能,大模型有了眼睛和嘴巴。今天我们再往前迈一步,智谱的大模型家族加入了一位新成员——GLM-4-Voice 端到端情感语音模型。
GLM-4-Voice 能够理解情感,有情绪表达、情感共鸣,可自助调节语速,支持多语言和方言,并且延时更低、可随时打断。
作为端到端的语音模型,GLM-4-Voice 避免了传统的 “语音转文字再转语音” 级联方案过程中带来的信息损失和误差积累,也拥有理论上更高的建模上限。
保持我们一贯的风格,发布即上线,大家可以在「智谱清言」上体验。
整体而言,GLM-4-Voice 具备以下特点:
情感表达和情感共鸣:声音有不同的情感和细腻的变化,如高兴、悲伤、生气、害怕等。
调节语速:在同一轮对话中,可以要求 TA 快点说 or 慢点说。
随时打断,灵活输入指令:根据实时的用户指令,调整语音输出的内容和风格,支持更灵活的对话互动。
多语言、多方言支持:目前 GLM-4-Voice 支持中英文语音以及中国各地方言,尤其擅长粤语、重庆话、北京话等。
结合视频通话,能看也能说:即将上线视频通话功能,打造真正能看又能说的AI助理。
从今天开始,GLM-4-Voice 会部署在清言 app 上。现在开始,你和清言的聊天会更加自然,它宛若真人,是一个靠谱的对话伙伴,能听懂你的情绪并回应。更值得期待的是,GLM-4-Voice 模型之后将与清言的视频通话能力合体,届时,像朋友一样陪你边看世界边聊天。
同时,GLM-4-Voice 发布即开源,这是我们首个开源的端到端多模态模型。
代码仓库:
与传统的 ASR + LLM + TTS 的级联方案相比,端到端模型以音频 token 的形式直接建模语音,在一个模型里面同时完成语音的理解和生成。
GLM-4-Voice 以离散 token 的方式表示音频,实现了音频的输入和输出的端到端建模。具体来说,我们基于语音识别(ASR)模型以有监督方式训练了音频 Tokenizer,能够在 12.5Hz(12.5 个音频 token)单码表的超低码率下准确保留语义信息,并包含语速,情感等副语言信息。语音合成方面,我们采用 Flow Matching 模型流式从音频 token 合成音频,最低只需要 10 个 token 合成语音,最大限度降低对话延迟。
预训练方面,为了攻克模型在语音模态下的智商和合成表现力两个难关,我们将 Speech2Speech 任务解耦合为 Speech2Text(根据用户音频做出文本回复) 和 Text2Speech(根据文本回复和用户语音合成回复语音)两个任务,并设计两种预训练目标,分别基于文本预训练数据和无监督音频数据合成数据以适配这两种任务形式:
Speech2Text:从文本数据中,随机选取文本句子转换为音频 token
Text2Speech:从音频数据中,随机选取音频句子加入文本 transcription
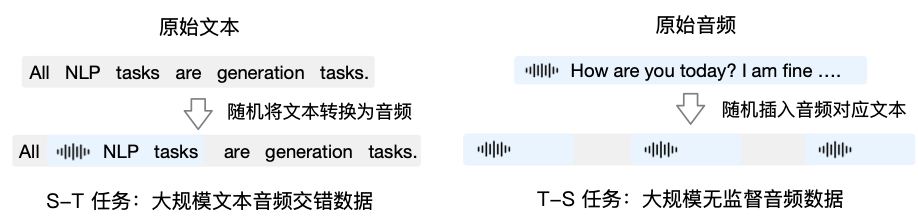
图|GLM-4-Voice 预训练数据构造
GLM-4-Voice 在 GLM-4-9B 的基座模型基础之上,经过了数百万小时音频和数千亿 token 的音频文本交错数据预训练,拥有很强的音频理解和建模能力。为了支持高质量的语音对话,我们设计了一套流式思考架构:输入用户语音,GLM-4-Voice 可以流式交替输出文本和语音两个模态的内容,其中语音模态以文本作为参照保证回复内容的高质量,并根据用户的语音指令变化做出相应的声音变化,在保证智商的情况下仍然具有端到端建模 Speech2Speech 的能力,同时保证低延迟性(最低只需要输出 20 个 token 便可以合成语音)。
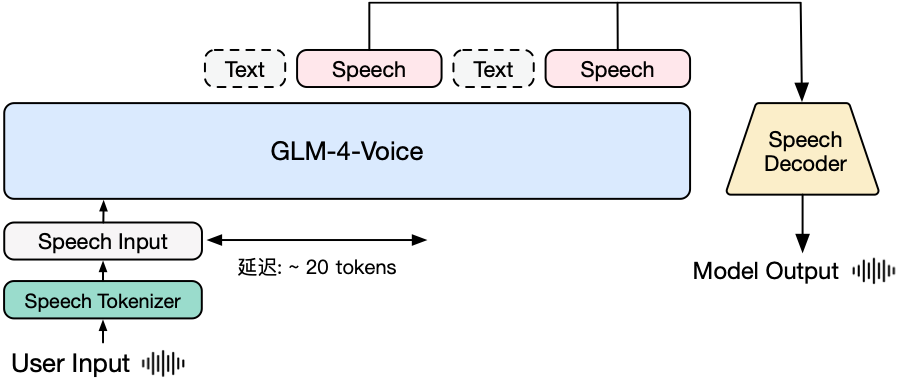
图|GLM-4-Voice 模型架构图
GLM-4-Voice 的出现是智谱在迈向 AGI 的道路上迈出的最新一步。
在使用工具方面。我们今天也带来了一个新的进展:AutoGLM。智谱一直希望模型的工具属性提升,能力边界持续扩大。于是非常自然的,我们想到了和用户接触最多的东西——手机。
这就是我们 AutoGLM 的 phone use 能力,只需接收简单的文字/语音指令,它就可以模拟人类操作手机。理论上,AutoGLM 可以完成人类在电子设备上可以做的任何事,它不受限于简单的任务场景或 API 调用,也不需要用户手动搭建复杂繁琐的工作流,操作逻辑与人类类似。
AutoGLM 基于智谱自研的「基础智能体解耦合中间界面」和「自进化在线课程强化学习框架」。其中的核心技术WebRL,克服了大模型智能体任务规划和动作执行存在的能力拮抗、训练任务和数据稀缺、反馈信号稀少和策略分布漂移等智能体研究和应用难题,加之自适应学习策略,能够在迭代过程中不断改进、持续稳定地提高自身性能。就像一个人,在成长过程中,不断获取新技能。
AutoGLM 在 Phone Use 和 Web Browser Use 上都取得了大幅的性能提升。例如,在 AndroidLab 评测基准上,AutoGLM 显著超越了 GPT-4o 和 Claude-3.5-Sonnet 的表现。在 WebArena-Lite 评测基准中,AutoGLM 更是相对 GPT-4o 取得了约 200% 的性能提升,大大缩小了人类和大模型智能体在 GUI 操控上的成功率差距。
目前,AutoGLM Web已经通过「智谱清言」插件对外发布,可以根据用户指令在网站上自动完成高级检索、总结与内容生成。手机端AutoGLM现已开启内测,暂时仅支持安卓系统。欢迎大家扫码申请体验。

从文本的一种模态,到包括图像、视频、情感语音模型在内的多模态,然后让AI学会使用各种工具,背后是我们的新的基座模型能力——GLM-4-Plus。在语言文本能力方面,GLM-4-Plus和GPT-4o及405B参数量的 Llama3.1 相当。
基于GLM-4-Plus,我们过去几年在多模态领域探索取得了一些阶段性成果。今天我们发布的GLM-4-Voice,让 GLM 多模态模型家族更加完整,为朝着原生多模态模型又迈出了一步。

面向 AGI 的分级,智谱也有自己的一些思考。L1 语言能力,L2 逻辑与思维能力,L3 工具能力大家是比较有共识的。我们认为 L4 级人工智能意味着 AI 可以实现自我学习、自我反思和自我改进。L5 则意味着人工智能全面超越人类,具备探究科学规律、世界起源等终极问题的能力。
人工智能多大程度上能够做到像人脑一样,甚至超越它?成为许多人所说的超级人工智能?从这个终极答案上看,我们大致也将在未来相当长的一段时间处于42%这个阶段。(42 这个百分比灵感来自《银河系漫游指南》,是关于生命、宇宙以及任何事情的终极答案。)
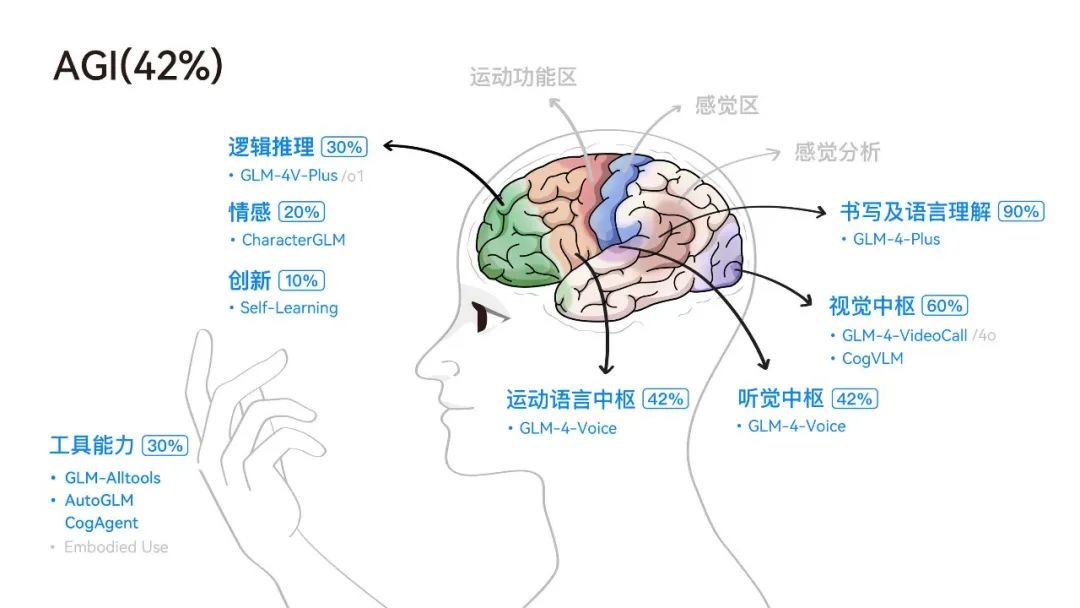
大脑是一个非常复杂的系统,包括听觉、视觉、语言等多模态的感知与理解能力,短期和长期记忆能力,深度思考和推理能力,以及情感和想象力。另外,作为人身体的指挥器官,大脑还懂得调动身体的各个部分协同运转,使用工具。
正如上面这张图上显示的,有些能力今天的GLM大模型已经解锁,比如文本,视觉,声音,比如一定的逻辑和使用工具的能力,有些模态的能力树还没有点亮,这些也是智谱未来会一直为之努力的方向。
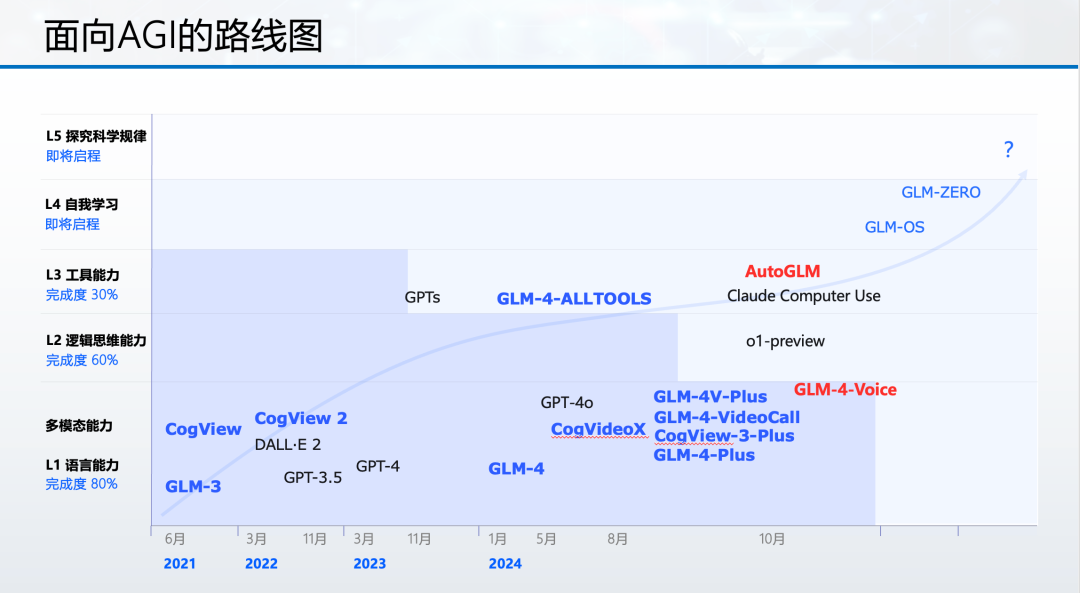
而我们面向 AGI 的技术升级曲线,实际上就是围绕大脑的能力维度展开的。从2021年以来,特别是最近一年多来的升级,大模型在L1 语言能力的方面完成的已经很好了(大概80%-90%)。
从语言能力再往上,事情就变得复杂。我们希望在不远的未来实现各种模态混合训练的原生多模态模型,它不仅在认知能力上比肩人类,同时能在价值观层面和人类对齐,确保 AI 的安全可控。智谱已经在这方面做了大量工作,将在适当的时候给大家及时公布进展。
AutoGLM 可以看作是智谱在 L3 工具能力方面的探索和尝试,希望我们的努力能够推动人机交互范式实现新转变,为构建 GLM-OS ,即以大模型为中心的通用计算系统打好基础。我们认为,大模型的工具能力最终应该像人类一样,感知环境、规划任务、执行动作(如使用工具/软件),最终完成特定任务。

原创文章,作者:王昊达,如若转载,请注明出处:http://damoai.com.cn/archives/7710