
大模型之家讯 日前,腾讯优图实验室与厦门大学联合发布了一项面向AI生成图像检测(AIGI)的研究成果,提出了全新的检测框架“AIGI-Holmes”。该方法以“大模型+视觉专家”的协同机制为核心,通过系统化的数据构建、训练流程和推理策略,首次实现对AI生成图像的高精度检测与可解释性描述,试图破解当前AIGI检测技术可解释性不足与泛化能力有限的瓶颈。


架构创新:“大模型+视觉专家”协同工作
AIGI-Holmes系统的核心架构引入“双视觉编码器”,在现有LLaVA基础上增设NPR视觉专家,以协同解析图像的高级语义特征与底层视觉伪影。同时,研究团队设计了三阶段的“Holmes Pipeline”训练流程:首先通过LoRA与全参微调完成视觉专家的预训练,再以大量自动生成的图文对进行监督微调(SFT),最后借助“直接偏好优化”(DPO)提升语言解释质量。此外,推理阶段采用协同解码策略,将多模态大语言模型(MLLM)与视觉专家的结果进行融合,有效提升模型在图像真实性判断上的精度与鲁棒性。
在协同解码中,研究团队赋予CLIP、NPR、MLLM三方不同的权重整合logit值,从而提升模型在未知场景中的适应性。该机制使检测结果不再只是“真/假”二值判断,而能够提供解释原因,改善了传统模型的“黑箱”问题。
数据构建与训练流程:从构建到优化的全流程设计
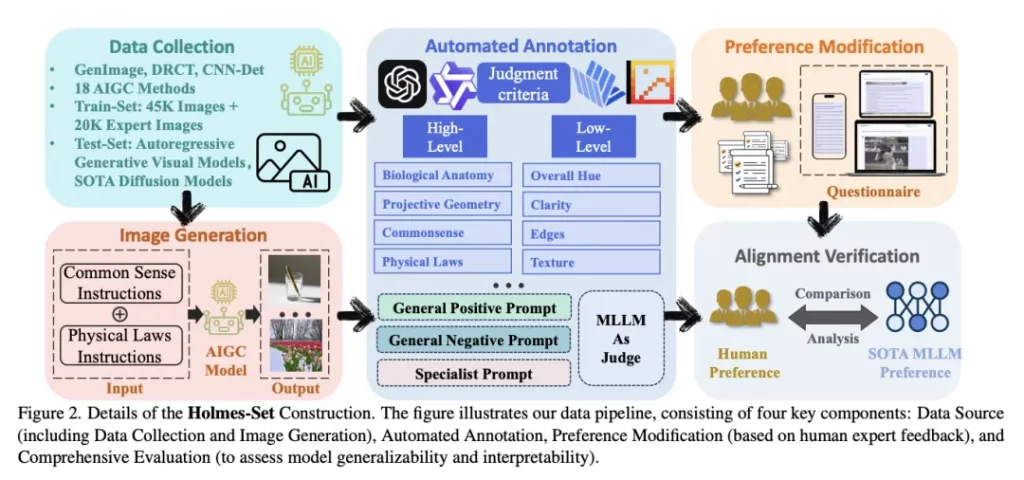
为了填补多模态训练数据的空白,团队自建了Holmes-Set数据集,包含4.5万张图像及2万条标注信息。数据涵盖常见的AIGI伪影类型,包括人脸结构异常、物理常识错误、文本渲染缺陷等,通过自动化标注流程生成,标注工具结合了四个SOTA大模型(如Qwen2VL、InternVL2等)的多轮评审。

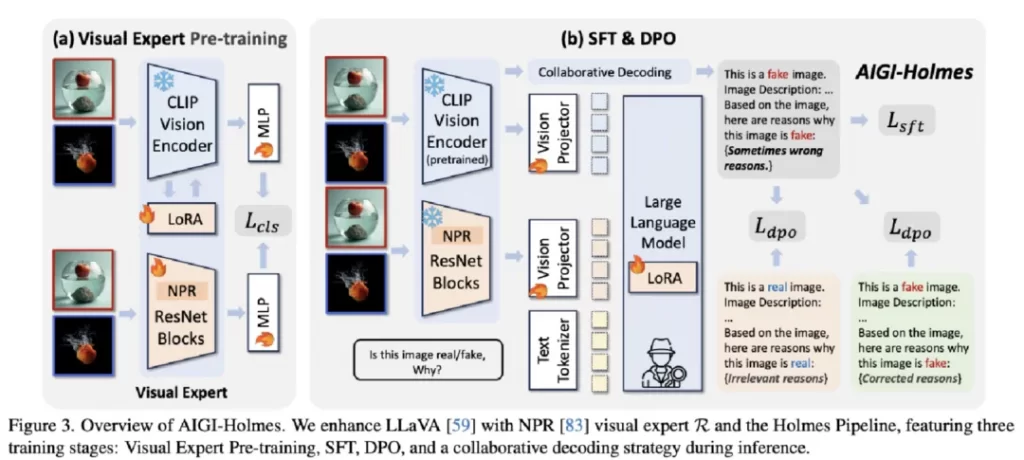
在训练阶段,研究团队采用多策略微调方式,SFT阶段主要训练语言解释能力,而DPO阶段则利用人类偏好数据对解释结果进行偏好修正,进一步抑制多模态模型常见的幻觉输出。特别值得注意的是,团队引入了“通用负向提示”机制,以制造反例训练数据,强化模型对错误解释的辨识能力。
检测与解释能力评估:多项指标均表现领先
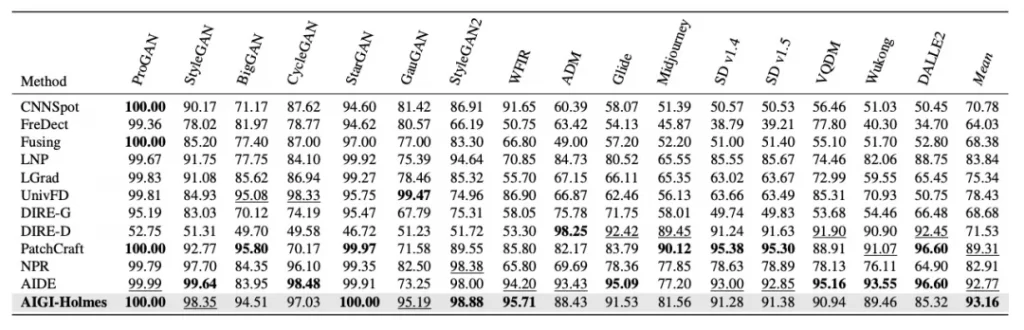
在标准检测任务上,AIGI-Holmes在三个主流数据集(AIGCDetect-Benchmark、AntiFakePrompt及一个新构建的第三方benchmark)上全面超越现有方法,表现出更高的准确率与平均精度。
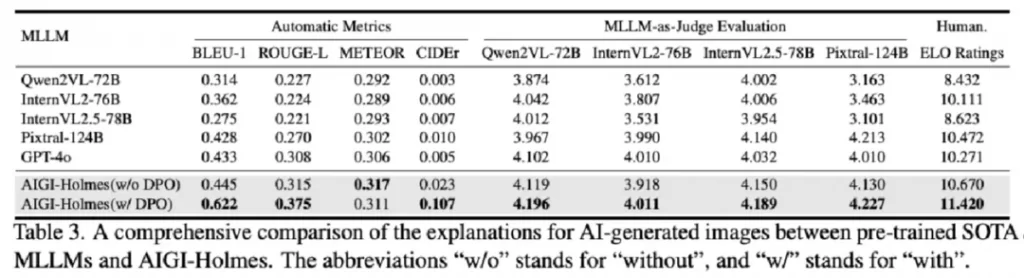
在可解释性评估方面,团队采用BLEU、ROUGE、CIDEr等文本生成指标,以及大模型评分与人工偏好打分双重体系进行评价。结果显示,该模型不仅生成内容在结构上更合理、语义上更贴切,也更符合人类偏好。
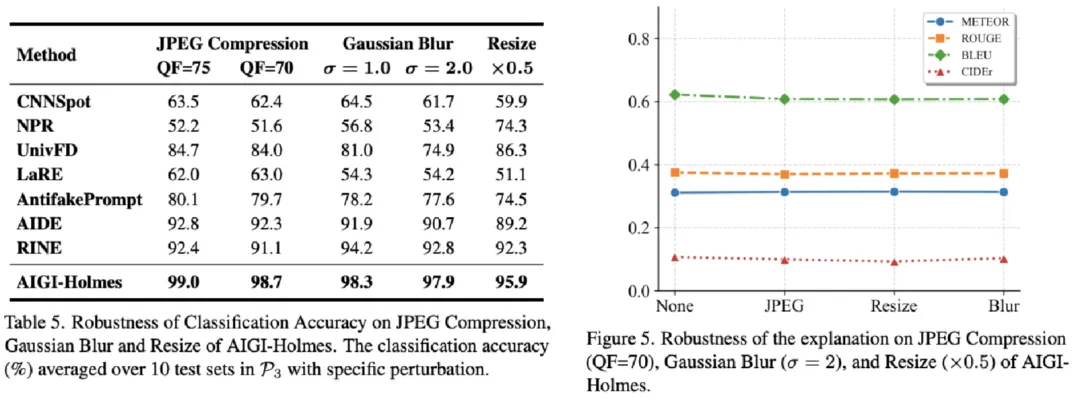
鲁棒性方面,研究团队引入JPEG压缩、高斯模糊和分辨率下采样等常见干扰因素,评估模型在图像退化场景下的稳定性。实验表明,AIGI-Holmes在识别能力与解释能力两个维度均保持了相对领先的鲁棒表现,显示出对现实场景更强的适应能力。
后续展望:从检测工具向内容可信机制演化
尽管AIGI-Holmes在多项任务中均取得优异成绩,但研究团队也指出,当前模型仍存在幻觉输出、细粒度缺陷识别难、解释评价标准不统一等问题。未来工作将聚焦于多模态模型的幻觉抑制、视觉理解粒度的提升以及建立更客观、低成本的解释评价体系。
在AIGC生成能力迅速跃迁、虚实难辨的背景下,这项研究不仅为图像内容审核与溯源提供了具备可解释性的技术工具,也提示着多模态大模型将在内容安全中扮演更核心的角色。从“检测”到“理解”,AI图像识别正迈入一个更复杂但也更可控的阶段。
开源链接
代码仓库:https://github.com/wyczzy/AIGI-Holmes
论文原文:https://arxiv.org/pdf/2507.02664
(内容来源:腾讯优图实验室)
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/11600