
4 个人围着 1 张桌子、1 台电脑,AI 史上“最寒酸”的 OpenAI 系列发布会,一开就是 12 天。前 11 天可以说是“寡淡无味”,而最后一天压轴登场的 o3 模型,结结实实给 AI 界来了个王炸。总结来说,这次的 o3 模型:很会编程,很会数学,不是 AGI,贵得离谱。
接下来详细说说 o3,关于前面 11 天的发布内容,我放在后面讲。
一、o3 模型
(一)很会编程
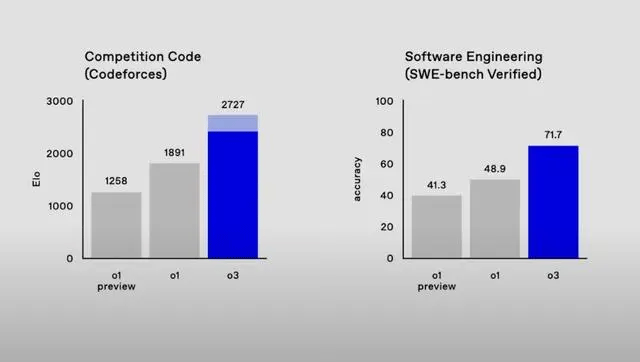

左为 Codeforces 测试评分,右为SWE-Bench Verified 测试评分
Codeforces(简称 CF)是一个面向全球程序员的在线编程竞赛平台,用户通过参加平台上的比赛和练习题目来提升编程技能和算法能力,每个用户在 CF 上都有一个相应的积分和等级。
在 CF 编程测试中,o3取得了 2727 分的 Elo 评分,比 o1 正式版高 44%,是 o1 预览版的两倍多。而在 OpenAI 推出的 SWE-Bench Verified 代码生成评估基准中,o3 也取得了不俗成绩,其准确率达到了 71.7%,比 o1 模型高出 20% 以上。
o3 达到这个评分意味着什么呢?放在 CF 平台全球排名系统中看,相当于在人类程序员编码竞赛中位列第 175 名,超过了 OpenAI 现任首席科学家 Jakub Pachocki(雅库布·帕乔基) 的 2655 分。
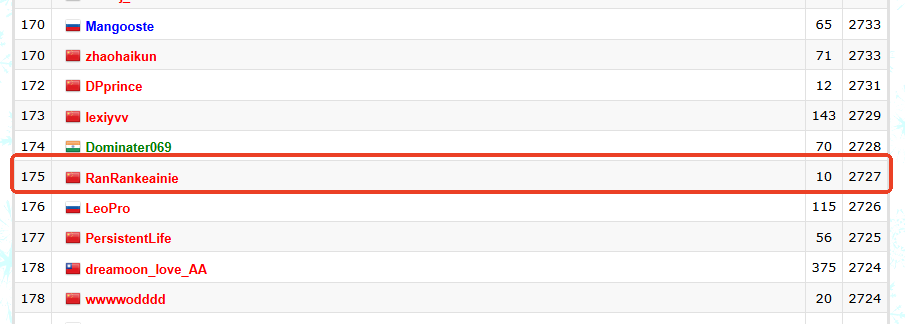
官方链接:https://codeforces.com/ratings/page/1
而在 CF 平台,目前有 168076 名来自全球各地的程序员参赛,o3 排名到第 175 名,意味着在编程竞技中击败了世界上约 99.9% 的程序员(1-175/168076)。
要知道之前爆火的 GPT-4o 在 CF 编程测试中得分也才打败了世界上 11% 的程序员,强如 o1 也仅仅打败了 93% ,而 o3 直接给干到了超越 99.9%。
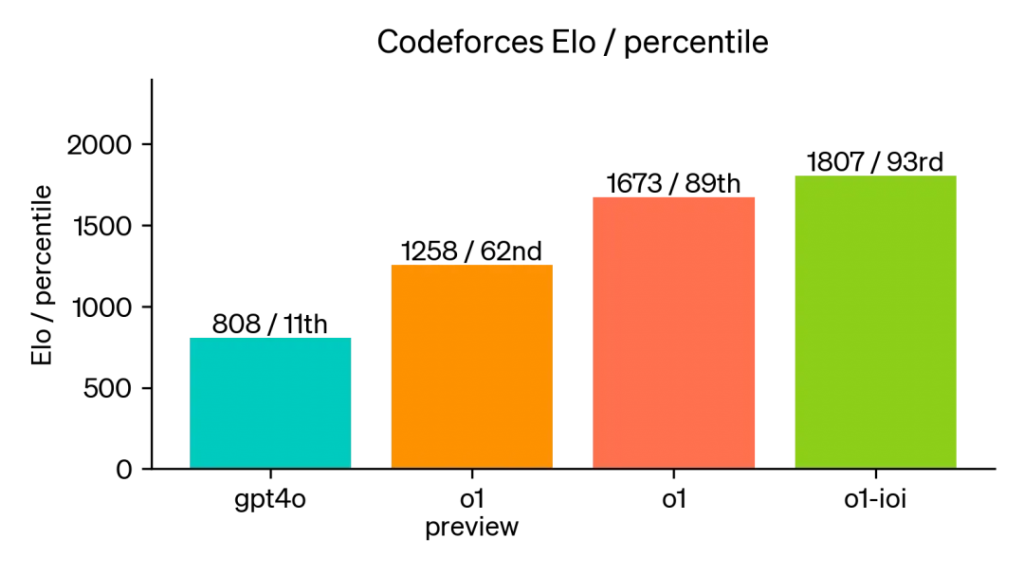
GPT-4o/o1-preview/o1/o1-ioi 在 CF 编程测试中得分
(二) 很会数学
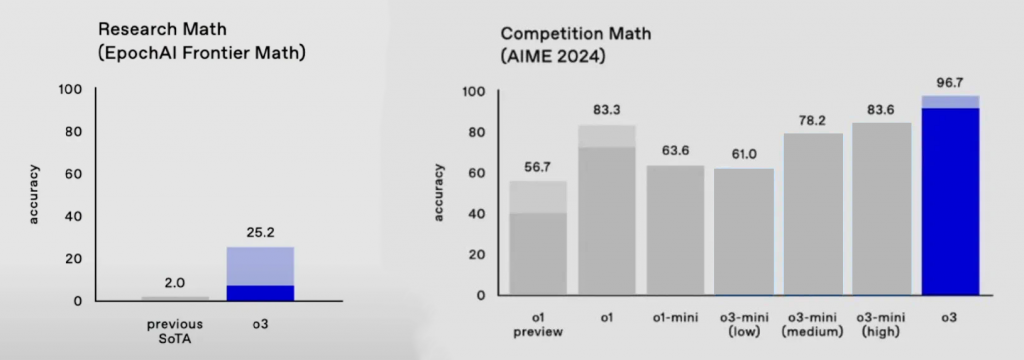
左为 FrontierMath 测试得分,右为 AIME 2024 测试得分
FrontierMath 是一个用于评估人工智能高级数学推理能力的基准测试,被誉为当今最具挑战性的数学基准测试之一,其具有三个关键的设计原则:
- 所有问题都是新的且未发表的,以防止数据污染;
- 解决方案是自动可验证的,从而实现高效的评估;
- 问题是“防猜测”的,在没有正确推理的情况下解决的可能性很低。
即使是经验丰富的数学专家,也得绞尽脑汁,花费数小时甚至数天才能解出来。著名数学家陶哲轩(Terence Tao)更是评价道:“这项测试可能会让 AI 难住好几年。”
在大模型爆发的前三年里,FrontierMath 已经让 o1、Claude 3.5 Sonnet、GPT-4o,Grok 和 Gemini 1.5 Pro 在测试中几乎“全交白卷”,最好成绩是解决了 2% 的问题,而 o3 解决了 25.2% 的问题。
同样,在其他数学推理能力的测试中,o3 的成绩也有显著提升。例如,在美国数学邀请赛 AIME 2024 数学基准测试中,o3 的准确率达到 96.7%,而 o1 的准确率为 83.3%,GPT-4o 更是只解决了13%的问题。
这意味着什么呢?它相当于 o3 在美国数学奥林匹克竞赛上,只答错了 1 道题。
(三)不是 AGI
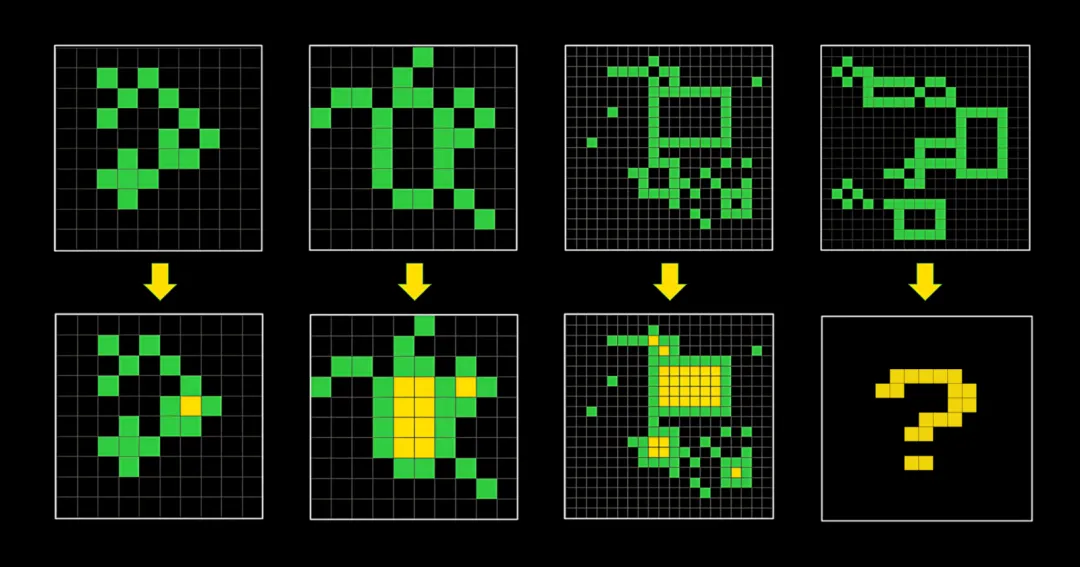
ARC-AGI 测试
ARC(Abstraction and Reasoning Corpus),是人工智能领域的一个重要基准,目标是评估 AI 系统在处理首次遇到的极其困难的数学和逻辑问题时的能力,要求 AI 模型具备学习新规则的能力,而不仅仅是重复记忆。最开始发表在论文《On the Measure of Intelligence》。地址: https://arxiv.org/abs/1911.01547
测试的主要形式,就是图形逻辑推理。每轮举出 3-5 个例子,图形的大小为从 1×1 到 30×30 的任意大小的网格图形,让 AI 根据图形变化的规律,预测出下一个图形的形式。地址:https://gitcode.com/gh_mirrors/ar/ARC-AGI
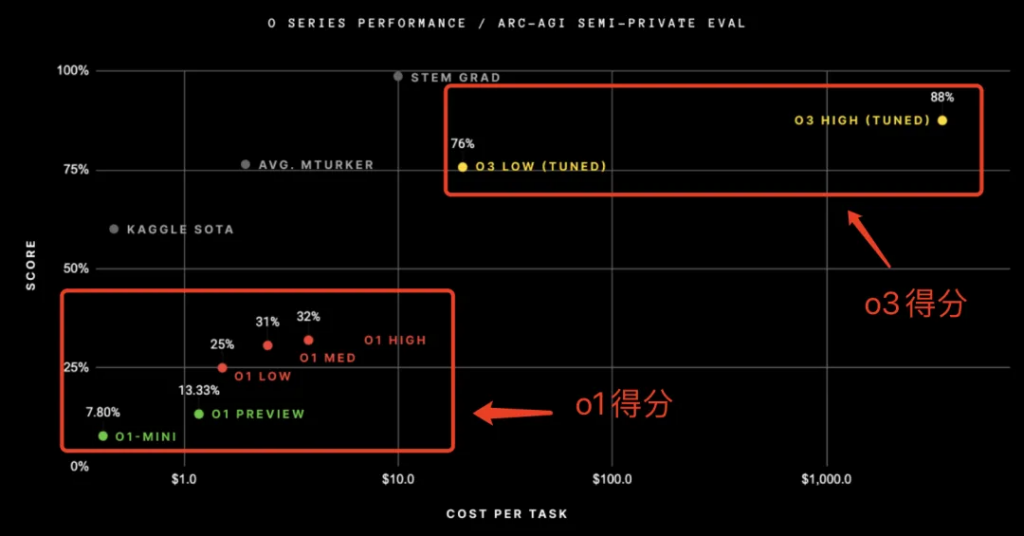
o 系列模型在 ARC-AGI-1 测试中得分,Y 轴为得分
在这场测试中,o3-high(高计算量模式)达到了 87.5% 的高分,o3-low(低计算量模式)也取得了 75.7% 的优异成绩,而 o1 各版本在同一测试中的得分分别为 mimi 7.8%,preview 13.33%,low 25%,med 31%,high 32%。
o3 这一成绩不仅远超之前的模型,更是接近了人类在这项测试中达到的分数阈值 85%。不过,这不代表 o3 已经达到了人类智能水平。ARC 官方表示:o3 会在一些非常简单的任务中失败,和人类智能还存在根本性的差别,因此尚未达到真正的 AGI 水平。
同时,ARC 还表示:在尚未对外发布的 ARC-AGI-2 测试中,人类的基准成绩是 95%,而 o3-high 的成绩会跌到不足 30%。
也就是说,在排除大模型不会“马虎”的前提下,越简单的题,人类答对的越多,o3 反而不会了。
关于 Claude 和 OpenAI 在 ARC-AGI 的测试结果,查看地址:https://github.com/arcprizeorg/model_baseline/tree/main/results
对了, o3 在 ARC-AGI 测试中未解决的问题,我放在了文末,大家可以去测试看看,o3 的水平是不是真的达到了人类智能。(反正小编全部解答出来了)
(四)贵得离谱
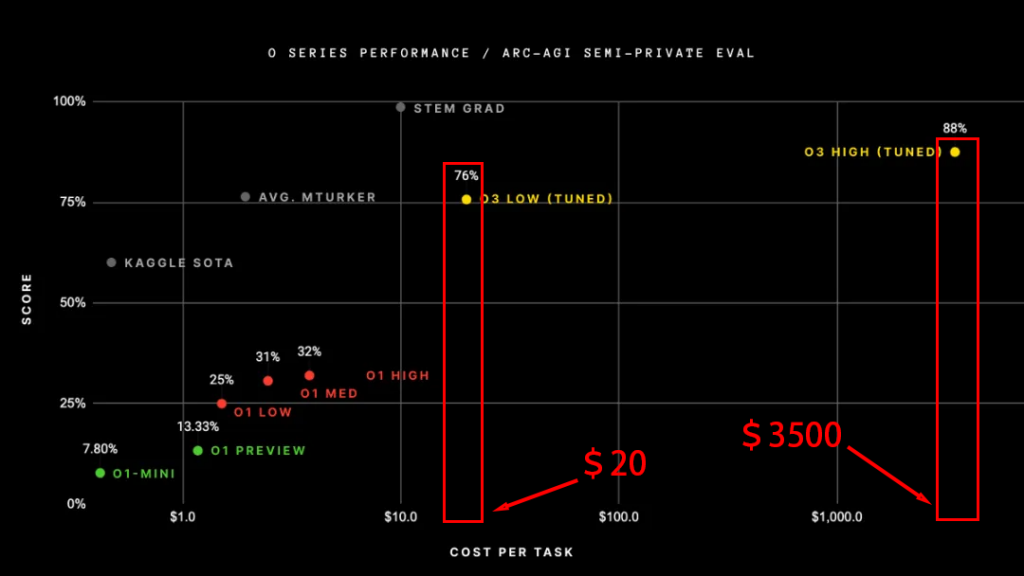
o 系列模型在 ARC-AGI-1 测试中的成本,X 轴为成本,单位美元
这次是刷新认知的贵。
还是根据 ARC-AGI 测试标准,o3-low 每个任务需要 20 美金,o3-high 每个任务数千美金。而根据计算量估算的话,o3-high 的成本大概 3500 美金,也就是说“点一次 Enter 键”,2 万人民币就没了。哪怕你问的是“1 加 1 等于几”,也是 2 万。
对比来看,o3-low 单任务成本是 o1-low 的 10 倍,o3-high 单任务成本是 o1-high 的 2000 倍。尽管 o3 在编码测试、数学竞赛等方面表现出色,但从成本效益角度看,其价格的增长幅度远超性能的提升幅度。
而从 OpenAI 的定价策略来看,3 个月前 o1-preview 版本刚出来的时候,其 API 每 100 万个输入 token 收费 15 美元,每 100 万个输出 token 收费 60 美元。现在每月支付 200 美元,就能无限使用 o1,并且可用 o1 pro mode。
估计随着技术发展,o3 的成本将快速下降,这为未来 AGI 的实现提供了经济上的可能性。
附o3模型测试申请:
https://openai.com/index/early-access-for-safety-testing
二、o3 模型对 AGI 的意义
关于 AGI 概念的标准,在不同领域和学科对人类智能的构成可能有不同的观点,但通常与 AGI 相关的能力包括:
- 在不确定的情况下进行推理、规划和问题解决
- 使用常识性知识从数据和经验中学习用自然语言进行交流
- 整合多种技能以实现共同目标
而 ARC-AGI 的创建者 François Chollet(弗朗索瓦·肖莱)认为:真正的智能不是你会多少技能,而是你有多会学习。毕竟,现在的大模型,你只要给他足够的数据,他就会有对应的技能,看不出到底有多聪明。
于是才有了前面的测试,用来评估那些 “没有出现过的问题”,也是目前唯一一个专门测量 AGI 进展的测试。以下是 Chollet 对 o3 模型得分高的看法:
0 强大的推理能力和任务适应能力:
传统大语言模型采用 “记忆 – 获取 – 应用” 的范式,在适应新环境或即时掌握新技能方面存在局限。而 o3 开创了全新的方法,如在 token 空间内进行自然语言程序的搜索和执行,使用类似 AlphaZero 的蒙特卡洛树搜索方法,并通过评估器模型引导搜索过程。
这种创新使 o3 能够实时生成和执行解决方案程序,通过思维链实现知识的动态重组,展现出类人的任务适应能力。
ps: 关于AlphaZero 的蒙特卡洛树搜索方法可以看 AlphaGo Zero 的论文《Mastering the Game of Go without Human Knowledge》①和 AlphaZero 的论文《Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm》②。
① https://deepmind.com/documents/119/agz_unformatted_nature.pdf
② https://arxiv.org/pdf/1712.01815.pdf
0 为实现 AGI 提供新的思路和方法:
o3 的出现证明了 AI 进步不仅仅依赖于简单地扩大模型规模和增加训练数据,更关键的是架构创新。其创新的技术路线为整个 AI 行业提供了新的方向,证明了深度学习引导的程序搜索形式的可行性。
尽管 o3 模型取得了重大突破,但距离真正的 AGI 仍有一定差距,存在一些需要努力的方向。
限制 1:依赖自然语言。o3 仍然依赖自然语言指令而非可执行的符号程序,这限制了其在某些复杂任务中的表现。相比之下,可执行的符号程序能够更准确地描述和执行任务,提高模型的效率和准确性。
限制 2:缺乏交互能力。缺乏与现实世界的直接交互能力,无法像人类那样通过与现实世界的互动来学习和适应,这使得 o3 无法通过直接执行来评估自己生成的解决方案的有效性。
限制 3:简单任务出错。尽管 o3 在复杂任务中表现出色,但在一些非常简单的任务中仍会犯错,这表明其性能可能会出现较大波动,需要进一步优化和改进。
限制 4:高昂计算成本。如前文所述。
除了 o3,OpenAI 还推出了 o3-mini。它是 o3 更经济高效且性能导向的版本,在成本和延迟方面比 O1-mini 低得多,同时提供类似的功能。o3-mini 设置了低、中、高三种推理模式,用户能根据任务复杂度灵活调整模型的思考时间,这使得它在实际应用中更加灵活和实用,能够满足不同用户和场景的需求。
每次说到 AI,不能不提安全性。OpenAI 深知这一点,因此在发布 o3 和 o3-mini 的同时,向安全研究人员开放了早期访问权限,旨在通过更多实际应用测试,进一步提升模型的安全性和可靠性。OpenAI 还使用了一种新技术 “慎重对齐”,来使 o3 等模型符合其安全原则。通过 “私人思维链”,o3 被训练成在做出反应之前先 “思考”,对任务进行推理并提前规划,在较长时间内执行一系列动作,以找出更准确、更安全的解决方案。
OpenAI 预计 o3-mini 将于 1 月底左右向所有用户推出,而完整版 o3 模型还需要等通知。
三、OpenAI 发布会全程亮点回顾
Day1:o1 正式版与 ChatGPT Pro 登场
- o1 正式版相比之前的 o1-preview 版本更加完备,性能提升了 34%,主要错误率降低了 34%,并且支持多模态输入;
- ChatGPT Pro 订阅服务主要面向对 AI 性能要求更高的专业用户,提供无限制访问 o1 和专业版 o1 的权限。
Day2:强化微调技术发布
- 这是一种新的模型训练方法,支持用户使用少量的训练数据在特定领域创建专家模型,预计将于 2025 年春季开放给用户。
Day3:Sora 正式版上线
- Sora 能够根据文本描述生成高达 1080p 分辨率、最长 20 秒的视频,并提供了多种视频编辑功能,如故事板、Remix、Re-cut 等;
- 用户可以通过时间线指导视频中多个动作的创作,将多个视频场景合并为一个全新场景,生成具有创意的新内容。
Day4:ChatGPT Canvas 全面开放
- Canvas 从聊天工具升级为生产力工具,支持用户与 ChatGPT 在写作和编程方面进行协作,提供了一个共享画布,用户和 ChatGPT 可以共同编辑文档和代码;
- 它内置了几乎所有常用的 Python 库,支持图片识别,用户可以上传图片并生成相关的文本内容,实现了写作、审稿、编码和图片识别的全方位协作。
Day5:OpenAI 与苹果合作
- iPhone、iPad 和 Mac 用户可以通过 Siri 使用 ChatGPT 的功能,实现了语音命令完成复杂任务、智能写作工具升级以及利用视觉智能快速识别眼前物品等功能,国内的话,不出意外就是排除在外了。
Day6:高级语音模式增强
- ChatGPT 的高级语音模式带来了视频输入和实时屏幕共享功能,让用户与 ChatGPT 的交互更加自然和直观。
Day7:Projects 功能推出
- 允许用户创建特定项目,上传相关文件,设置自定义指令,并将所有与该项目相关的对话集中在一个地方,方便用户对项目进行管理和协作。

Day8:ChatGPT Search 全面升级
- ChatGPT Search 免费开放,强化了联网检索能力,使用户在与 ChatGPT 的对话中能够更方便地获取最新的信息和知识。
Day9:o1 推理模型开放 API
- 开放了 o1 推理模型的应用程序编程接口,降低了 o1 模型的使用成本。
Day10:电话使用 ChatGPT 功能上线
- 推出通过电话和 WhatsApp 使用 ChatGPT 的功能,降低了用户使用 ChatGPT 的门槛。
Day11:ChatGPT 与 Mac 应用深度集成
- ChatGPT 与 Mac 应用进行了深度集成,支持与 Warp、Xcode 等应用联动,并可在语音模式下与苹果备忘录等应用协同工作。
这 12 天的发布会,见证了 OpenAI 在人工智能领域的不断突破和进步,虽然距离最终的 AGI 还有一段距离,但让我们看到了未来 AI 发展的无限可能。
原创文章,作者:王昊达,如若转载,请注明出处:http://damoai.com.cn/archives/8499