

大模型之家讯 近日,清华大学自然语言处理(NLP)实验室的刘知远教授团队在人工智能领域取得了重要突破,他们提出了一种革命性的理论——大模型的“密度定律”(Densing Law)。这一理论不仅为理解和预测大模型的发展趋势开辟了新路径,还有望为人工智能技术的进一步创新与行业应用带来深刻变革,同时,它也为传统的规模法则(Scaling Law)提供了有益的补充。
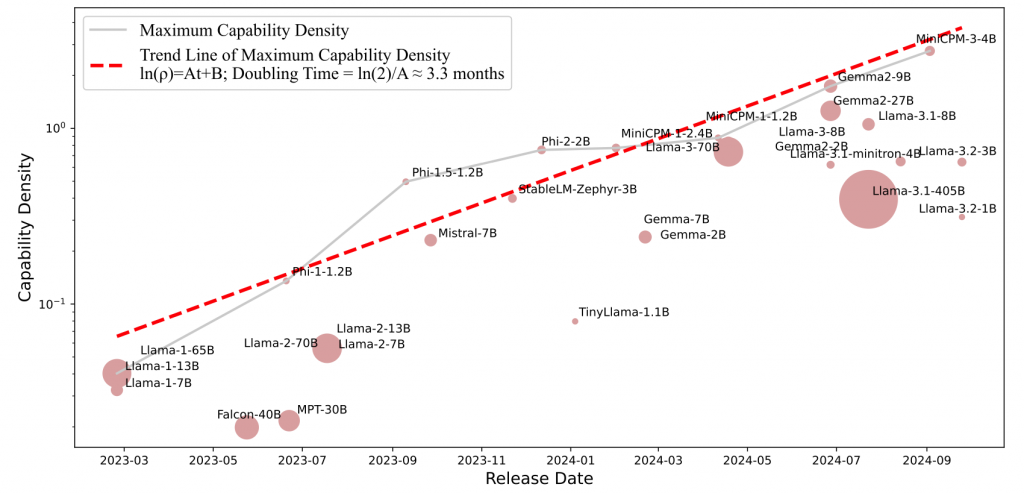
所谓“密度定律”,是指大模型的能力密度随时间呈指数级增长。自2023年以来,这一能力密度大约每3.3个月(即约100天)便实现翻倍,其增长速度之快,可与摩尔定律中集成电路晶体管密度的增长速度相媲美。刘知远教授团队通过引入“能力密度”这一创新指标,即“有效参数量”与实际参数量的比值,为评估不同规模的大模型提供了一个统一且全新的度量框架。这一发现打破了以往认为只有增加模型规模才能提升性能的固有认知,揭示了即便模型参数量减半,也有可能达到当前最先进模型的性能水平。
为了准确评估模型性能,研究团队采用了先进的两步估计法。首先,他们利用一系列不同规模的参考模型来拟合参数量与语言模型Loss之间的关系,进行初步的损失(Loss)估计;其次,考虑到涌现能力的存在,研究人员结合开源模型来计算它们的损失和性能,最终建立起精确的映射关系。这一方法的提出,使得对大模型性能的评估更为精确且可靠。
“密度定律”的提出,不仅揭示了AI时代的三大核心引擎——电力、算力与智力——都遵循密度快速增长的趋势,还为AI技术的行业应用提供了重要指导。它预示着,未来AI技术将更加注重效率与性能的提升,对能源和算力的需求将逐渐降低,从而推动AI技术在更多行业中的广泛应用。同时,这一发现也进一步证明了“规模法则并非描述大模型能力的唯一视角”。传统的规模法则虽然强调了模型规模和训练数据对人工智能能力的影响,但并未涵盖大模型发展的全部方面。而密度定律的提出,则为理解和预测大模型的发展趋势提供了更为全面且新颖的视角。
刘知远教授表示:“密度定律的提出,为我们提供了一个全新的视角来审视大模型的发展。我们相信,这一理论将有助于指导未来的AI研究和应用,推动人工智能技术向更高效、更智能的方向发展。同时,我们也期待这一理论能够为AI技术的行业应用提供更多的启示和借鉴。”
原创文章,作者:王昊达,如若转载,请注明出处:http://damoai.com.cn/archives/8227