
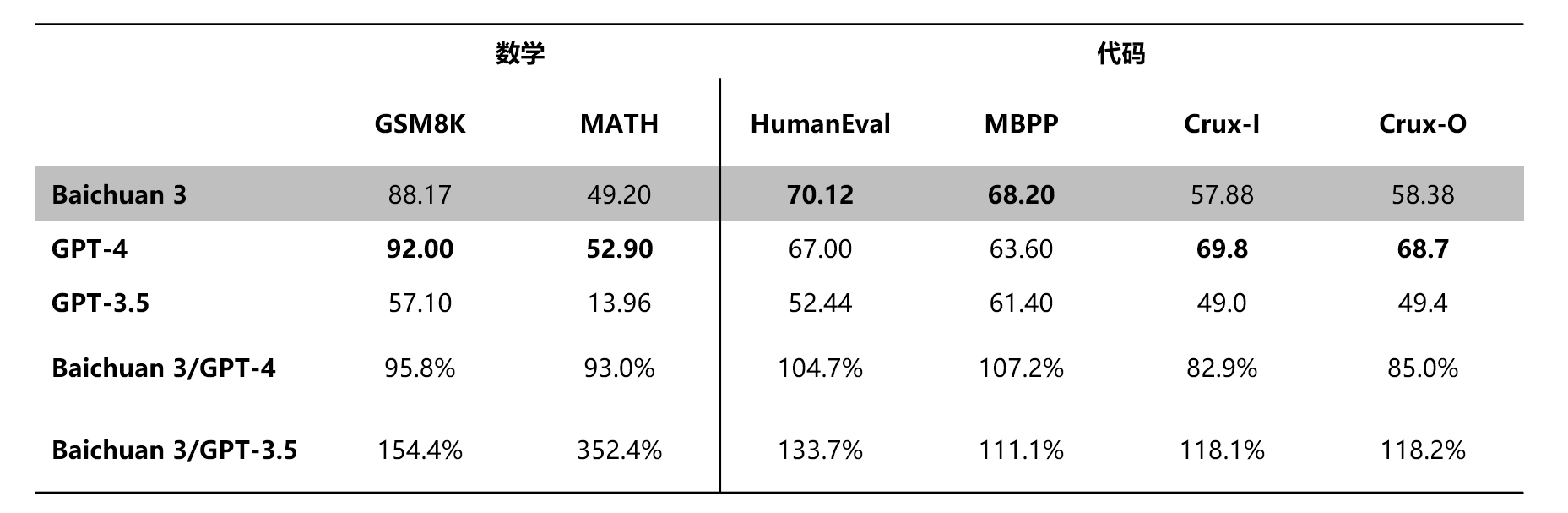
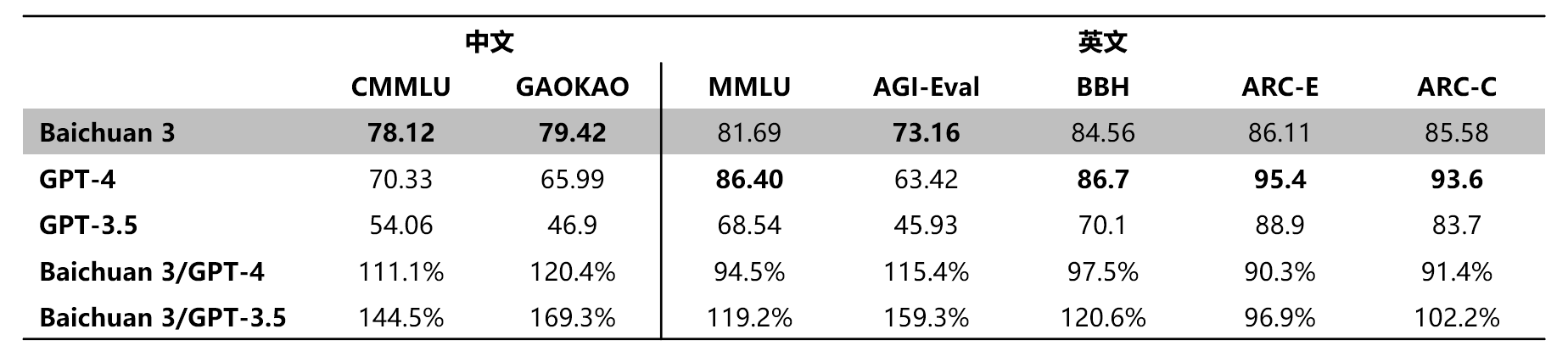
大模型之家讯 1月29日,百川智能发布超千亿参数的大语言模型Baichuan 3。在多个权威通用能力评测如CMMLU、GAOKAO和AGI-Eval中,Baichuan 3都展现了出色的能力,尤其在中文任务上更是超越了GPT-4。而在数学和代码专项评测如MATH、HumanEval和MBPP中同样表现出色,证明了Baichuan 3在自然语言处理和代码生成领域的强大实力。
不仅如此,其在对逻辑推理能力及专业性要求极高的MCMLE、MedExam、CMExam等权威医疗评测上的中文效果同样超过了GPT-4,是中文医疗任务表现最佳的大模型。Baichuan 3还突破“迭代式强化学习”技术,进一步提升了语义理解和生成能力,在诗词创作的格式、韵律、表意等方面表现优异,领先于其他大模型。
链接:https://www.baichuan-ai.com/
基础能力全面提升,多项权威评测中文任务成绩超越GPT-4
Baichuan 3在多个英文评测中表现出色,达到接近GPT-4的水平。而在CMMLU、GAOKAO、HumanEval和MBPP等多个中文评测榜单上,更是超越GPT-4展现了其在中文任务上的优势。

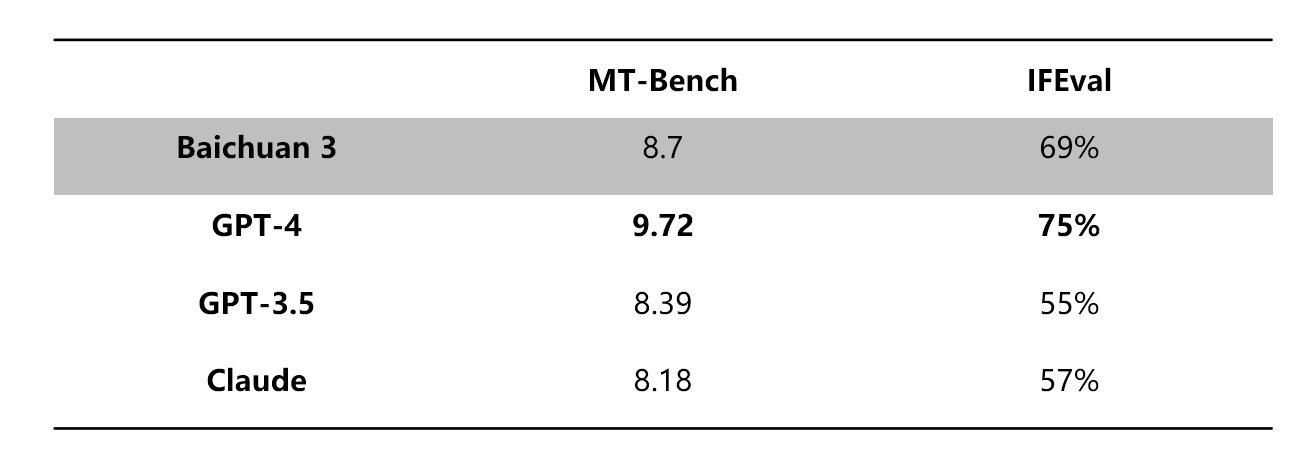
此外,在MT-Bench、IFEval等对齐榜单的评测中,Baichuan 3超越了GPT-3.5、Claude等大模型,处于行业领先水平。
与百亿、几百亿级别参数模型训练不同,超千亿参数模型在训练过程中对高质量数据,训练稳定性、训练效率的要求都高出几个量级。为更好解决相关问题,百川智能在训练过程中针对性地提出了“动态数据选择”、“重要度保持”以及“异步CheckPoint存储”等多种创新技术手段及方案,有效提升了Baicuan 3的各项能力。
高质量数据方面,传统的数据筛选依靠人工定义,通过滤重筛选、质量打分、Textbook筛选等方法过滤数据。而百川智能认为,数据的优化和采样是一个动态过程,应该随着模型本身的训练过程优化,而非单纯依靠人工先验进行数据的采样和筛选。为全面提升数据质量,百川智能设计了一套基于因果采样的动态训练数据选择方案,该方案能够在模型训练过程中动态地选择训练数据,极大提升数据质量。
训练稳定性方面,超千亿参数的模型由于参数量巨大,训练过程中经常会出现梯度爆炸、loss跑飞、模型不收敛等问题。对此,百川智能提出了“重要度保持”(Salience-Consistency)的渐进式初始化方法,用以保证模型训练初期的稳定性。并且优化了模型训练过程的监控方案,在梯度、Loss等指标上引入了参数“有效秩”的方法来提早发现训练过程中的问题,极大加速对训练问题的定位,确保了最后模型的收敛效果。此外,为了确保在数千张GPU上高效且稳定地训练超千亿参数模型,百川智能同步优化了模型的训练稳定性和训练框架,并采用“异步CheckPoint存储”机制,可以无性能损失地加大存储的频率,减少机器故障对训练任务的影响,使Baichuan 3的稳定训练时间达到一个月以上,故障恢复时间不超过10分钟。
训练效率方面,百川智能针对超千亿参数模型的并行训练问题进行了一系列优化,如高度优化的RoPE, SwiGLU计算算子;在数据并行中实现参数通信与计算的重叠,以及在序列并行中实现激活值通信与计算的重叠,从而有效降低了通信时间的比重;在流水并行中引入了将激活值卸载至GPU的技术,解决了流水并行中显存占用不均的问题,减少了流水并行的分段数量并显著降低了空泡率。通过这些技术创新,Baichuan 3的训练框架在性能方面相比业界主流框架提升超过30%。
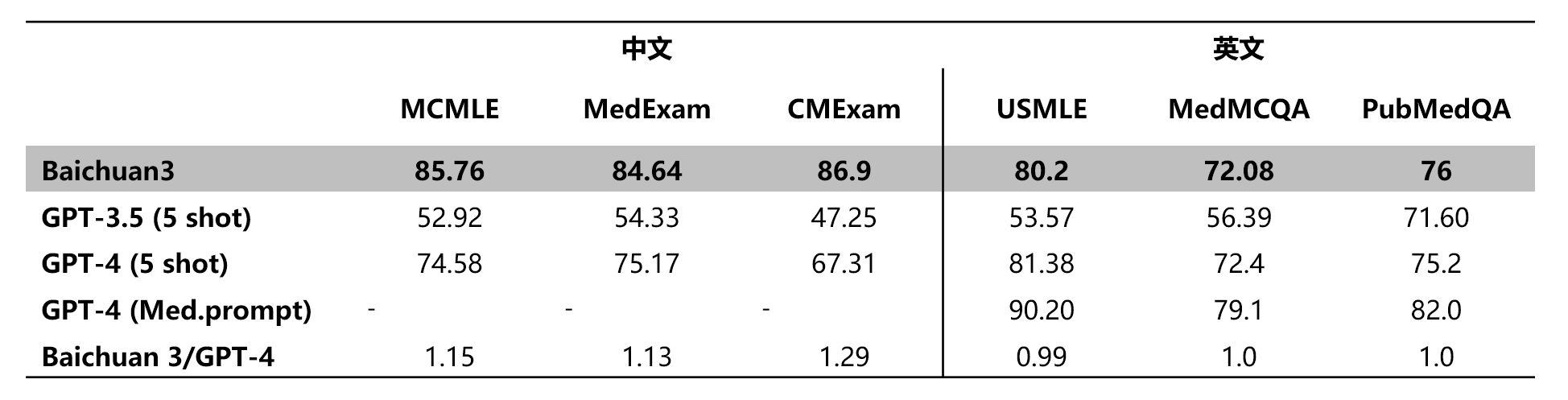
医疗数据集Token数超千亿,医疗能力逼近GPT-4
大模型医疗背后蕴含着巨大的社会价值和产业价值,从疾病的诊断、治疗到患者护理与药物研发,大模型不仅能够帮助医生提高诊疗效率和质量,帮助患者获得更好的服务和体验,还能帮助社会降低医疗成本和风险,助力医疗资源实现普惠和平权。并且医疗问题专业性强、知识更新速度快、准确性要求高、个体差异大,能充体现大模型的各项能力,被百川智能称为“大模型皇冠上的明珠”。因此,诸如OpenAI、谷歌等头部大模型企业都将医疗作为模型的重点训练方向和性能评价的重要体系。ChatGPT早在2023年2月便已通过了美国医学执照考试(USMLE),显示出其在医学领域的强大能力。而谷歌对医疗领域的重视更甚,基于PaLM模型打造了医疗大模型Med-PaLM,迭代后的Med-PaLM 2在医学考试 MedQA中的成绩超过80分,达到了专家水平。
在医疗领域,大模型的全能特性发挥着至关重要的作用。首先,其多模态学习能力能够整合文本、影像、声音等多种类型的医疗数据,提供更全面、准确的分析和诊断。其次,大模型的深层推理能力有助于复杂医疗决策的制定。此外,稳定的性能和知识更新能力确保了医疗建议的可靠性和时效性。同时,大模型的语言理解和生成能力使其能够处理专业术语和复杂句式。最后,模式识别与学习能力在大模型中的应用,使其能够从复杂的医疗数据中学习和识别出重要的模式和特征。所以,大模型想要在医疗领域拥有良好效果并不容易,既需要丰富的医疗知识、合适的Prompt,还需要模型本身具备过硬的逻辑推理能力。
为了给Baichuan3注入丰富的医疗知识,百川智能在模型预训练阶段构建了超过千亿Token的医疗数据集,包括医学研究文献、真实的电子病历资料、医学领域的专业书籍和知识库资源、针对医疗问题的问答资料等。该数据集涵盖了从理论到实际操作,从基础理论到临床应用等各个方面的医学知识,确保了模型在医疗领域的专业度和知识深度。
针对医疗知识激发的问题,百川智能在推理阶段针对Prompt做了系统性的研究和调优,通过准确的描述任务、恰当的示例样本选择,让模型输出更加准确以及符合逻辑的推理步骤,最终不仅提升了Baichuan 3在多项医疗考试上的成绩,并且在真实的医疗问答场景下也能给用户提供更精准、细致的反馈。
逻辑推理方面,Baichuan 3在数学和代码等多个权威评测上中文任务超越GPT-4的优异成绩,已经充分证明了其强大的基础逻辑推理能力。在拥有丰富高质量专业医疗知识,并能通过调优后的Prompt对这些知识进行充分激发的基础上,结合超千亿参数的推理能力,Baichuan 3在医疗领域的任务效果提升显著,在各类中英文医疗测试中的成绩提升了2到14个百分点。
Baichuan 3在多个权威医疗评测任务中表现优异,不仅MCMLE、MedExam、CMExam等中文医疗任务的评测成绩超过GPT-4,USMLE、MedMCQA等英文医疗任务的评测成绩也逼近了GPT-4的水准,是医疗能力最强的中文大模型。
突破“迭代式强化学习”技术,创作精准度大幅提升
语义理解和文本生成,作为大模型最基础的底层能力,是其他能力的支柱。为提升这两项能力,业界进行了大量探索和实践,OpenAI、Google以及Anthropic等引入的RLHF(基于人类反馈的强化学习)和RLAIF(基于AI反馈的强化学习)便是其中的关键技术。
基于强化学习对齐后的模型不仅可以更精准地理解用户指令,尤其是多约束以及多轮对话下的指令,还能进一步提升生成内容的质量。但是在大模型中充分发挥强化学习的作用不仅需要稳定且高效的强化学习训练框架和高质量的优质偏序数据,还需要在“探索与利用”两者间进行平衡,实现模型能力持续爬坡。
对于以上问题,百川智能进行了深入研究,并给出了针对性的解决方案。强化学习训练框架方面,百川智能自研了训练推理双引擎融合、多模型并行调度的PPO训练框架,能够很好支持超千亿模型的高效训练,训练效率相比业界主流框架提升400%。偏序数据方面,百川智能创新性的采用了RLHF与RLAIF结合的方式来生成高质量优质偏序数据,在数据质量和数据成本之间获得了更好的平衡。在此基础上,对于“探索与利用”这一根本挑战,百川智能通过PPO探索空间与Reward Model评价空间的同步升级,实现“迭代式强化学习”(iterative RLHF&RLAIF)。基于强化学习的版本爬坡,可以在SFT的基础上进一步发挥底座模型的潜力,让Baichuan 3的语义理解和生成创作能力大幅提升。
以文本创作中最具挑战的唐诗宋词为例,作为中国传统文化的瑰宝,诗词不仅在格式、平仄、对偶、韵律等方面均有着严格的约束条件,并且内容高度凝练、寓意深远。如果仅通过SFT的微调学习,一方面高质量诗词的创作数据需要极高的专家成本,另一方面不能在平仄、对偶、韵律等多个方面实现较好的约束理解和遵循。此外,传统的单次RLHF范式在唐诗宋词面前也遇到极大挑战,PPO在训练过程中生成的Response有可能超出Reward Model的评价范围导致“探索”的过程失控。
Baichuan 3结合“RLHF&RLAIF”以及迭代式强化学习的方法,让大模型的诗词创作能力达到全新高度。可用性相比当前业界最好的模型水平提升达500%,文采远超GPT-4。对于宋词这种格式多变,结构深细、韵律丰富的高难度文体,生成的内容亦能工整对仗、韵脚和谐。其精准、深厚的创作功底,将让每个人都能够轻松创作出咏物、寄思的五言律诗、七言绝句,写下的言志、抒情的“沁园春”、“定风波”,这不仅可以提升大众的人文素养,还能助力中华传统文化在大模型时代真正地“活”起来。

作为参数规模超过千亿的大语言模型,Baichuan 3不仅英文效果达到接近GPT-4的水平,还在多项通用中文任务的表现上实现了对GPT-4的超越,是百川智能的全新里程碑。Baichuan 3全面的通用能力以及在医疗领域的强大表现,将为百川智能打造“超级应用”,把大模型技术落地到诸多复杂应用场景提供有力支撑。
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/3301