


在2023年的最后一个月,谷歌在社交平台上“低调”的官宣了新一代大模型Gemini。不过Gemini一经上线便吸引下了行业内外人士的广泛关注,很多观点都表达出Gemini将成为GPT-4最强劲的对手,甚至碾压GPT-4的存在……
根据官方介绍Gemini已经实现各项参数超越GPT-4,特别是多模态领域包括图像、视频音频等领域都有着突出的领先优势。并且Gemini是第一个在MMLU(大规模多任务语言理解)方面优于人类专家的模型,而MMLU也是测试AI模型知识和解决问题能力的最流行方法之一。
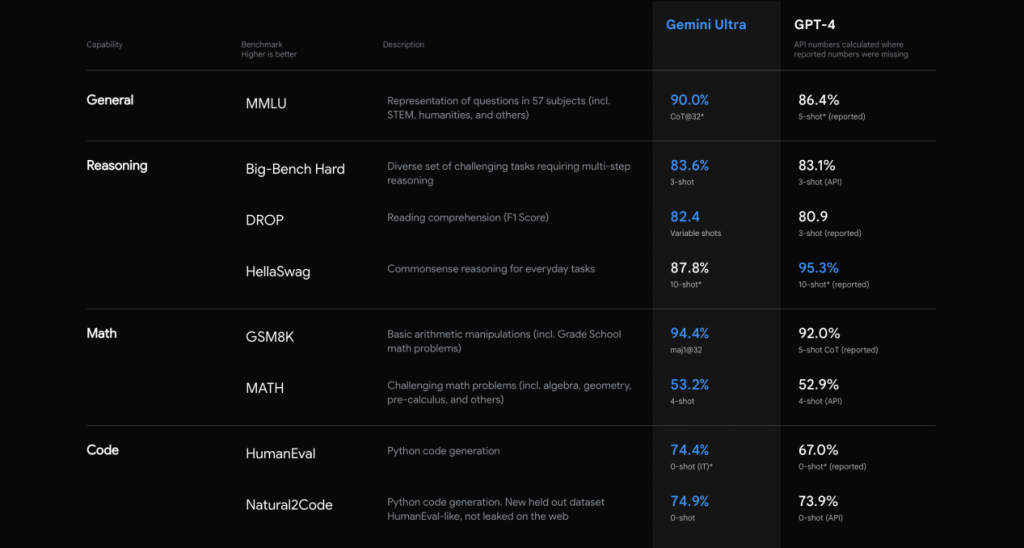
从数据上来看,Gemini在自然语言处理、智能对话系统、信息检索等领域,可以使其更好地适应和解决复杂的语境和任务。强大语言处理能力还可以为人们提供更高效、精准的信息和服务。
今天,谷歌官方表示Google AI Studio和Google Cloud Vertex AI将把Gemini模型集成到应用程序中。同时,用户可以在Bard中体验集成了Gemini Pro的测试版本大模型。值得一提的是,在Gemini AI官方介绍Gemini是Google即将推出的AI模型,由DeepMind和Google Brain联合AI团队的专家创建。同时Gemini AI也郑重声明“Gemini AI”的名称是 Google 的财产,且不隶属于 Google AI。
视觉新体验,多模态功能成新发力点
在众多功能展示中,Gemini最受业内外人士以及媒体关注的便是其多模态能力带来的体验,在官方介绍视频中,Gemini可以对正在变化的视频进行分析和理解,并且形成相应的描述。同时,在给出相应文字介绍时,Gemini还通过音频的形似对文字内容进行复述,在复述的过程中还包含了一些拟人形态的气口、停顿以及趣味性的对话,使得模型与使用者的交流更加顺畅自然。

在大模型之家的体验中,大模型之家使用对集成了Gemini Pro的大模型Bard给出了部分《清明上河图》的图片作为指令,让Bard进行识别。Bard也清晰的给出了对于图片的识别和描述。

除了介绍了《清明上河图》的内容,集成了Gemini Pro的大模型Bard还总结了《清明上河图》的主题。它表示:画中描绘了北宋汴京城的繁华景象,展现了北宋时期的经济繁荣和社会稳定。
Gemini能够同时处理多种类型的数据,包括文本、图像和视频,从而实现更丰富和全面的信息理解和表达。这种能力的实现,依赖于Gemini的底层架构可以将不同的数据源转换为相同的向量表示,然后再根据不同的任务生成相应的输出。这种架构的优势在于,它可以利用不同数据源之间的关联性和互补性,提高模型的泛化能力和创造力。
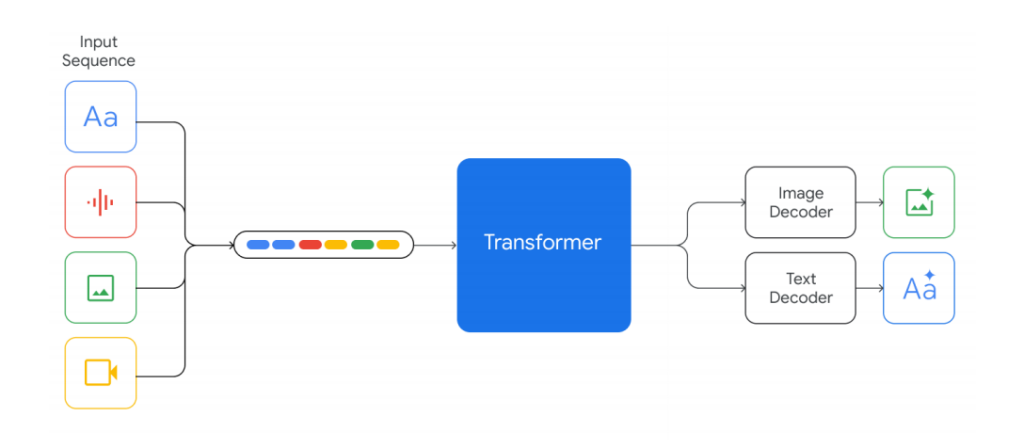
在图像识别和描述能力上,Gemini通过多模态架构与应用相结合,使用了一些先进的计算机视觉和自然语言处理的技术,如目标检测、场景分割、图像字幕、文本摘要等,来实现图像到文本的转换,并且在文本中包含一些图像的重要信息和细节。这种结合的优势在于,它可以提高模型的准确性和完整性,展示模型的分析和理解能力。
多尺寸部署,为商业化打好前站
在首批公开的信息中,Gemini同时提出了三种不同尺寸的大模型,由大到小分别为Gemini Ultra、Gemini Pro以及Gemini Nano。

其中,Gemini Ultra是Gemini系列中最大、最强的模型,拥有超过1000亿的参数,可以处理高度复杂的任务,例如高级推理、规划、理解等。而通过MMLU的测试的也正是Gemini的Ultra版本。
据大模型之家了解,谷歌采用了自研TPU为Gemini的提供模型训练,根据Gemini模型的大小和配置,谷歌为其配置了大型的TPUv4加速器群,用于进行机器学习和深度学习任务。TPU的设计旨在提供高效的张量计算,使其在训练和推理深度学习模型方面能够取得卓越的性能。

TPUv4加速器的部署方式,即以4096芯片为单位的”SuperPods”。每个SuperPod都与专用光纤交换机连接,能够在短时间内动态重新配置芯片,形成3D环形拓扑结构。而Gemini Ultra,在每个SuperPod中保留一小部分芯片,以支持热备份和滚动维护。谷歌通过采用自主研发的硬件加速器成功摆脱对英伟达等企业的算力依赖,从而在算力方面取得了更好的成本效益。这不仅实现了降低成本,还提高了效率。
而作为现在就可以体验到的Gemini Pro也是Gemini系列中最平衡的模型,它拥有约100亿的参数,可以扩展到多种任务,例如文本生成、图像描述、代码编写等。在集成到Bard后,大模型之家明显的感觉到Gemini Pro任务处理速度以及多模态能力的提升。
除此之外,Gemini 还推出了可以运行在设备端,例如移动手机、平板电脑等场景的小尺寸模型Gemini Nano,拥有约10亿的参数,可以为用户提供一些便捷的AI功能,例如摘要、翻译、智能回复等。

目前,Gemini Nano已经接入谷歌旗下手机产品Pixel 8 Pro,用户可以通过Recorder和Gboard等应用来体验Gemini Nano。Gemini AI设计了专为设备端部署而设计的Gemini Nano 1和Nano 2两个模型。Nano-1和Nano-2模型的参数规模分别仅为1.8B和3.25B。尽管规模相对较小,但在检索相关任务上表现出色,并在推理、STEM(科学、技术、工程、数学)、编码、多模态和多语言任务中显示出显著的性能。这些模型在摘要生成和阅读理解任务中表现优秀,并通过每个任务的微调来进一步优化性能。
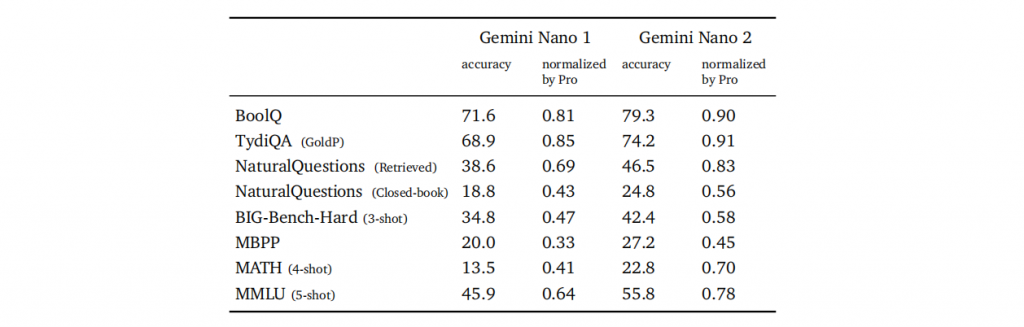
在商业化道路上,Gemini系列的多尺寸模型允许谷歌为不同行业和用户需求提供定制化的解决方案。Gemini Ultra的大规模模型适用于处理复杂的高级任务,可以提供个性化的服务,而Gemini Pro和Nano则更灵活,适用于广泛的应用场景,包括移动设备、智能家居等,为用户提供更加个性化、综合性的体验。
通过多重部署方式,Gemini模型扩大了对所有人的可访问性。大模型之家认为Gemini模型的多尺寸设计有助于构建更为强大和多样化的AI生态系统。将不同尺寸的Gemini模型引入到开发者和合作伙伴生态系统中,可以为谷歌激发更多创新,鼓励开发者在各个领域中应用Gemini模型,从而进一步扩大其在人工智能领域的影响力。
随着Gemini的落地,谷歌想要在大模型领域,巩固大厂“强者恒强”的优势。对于OpenAI的GPT与Meta的LLama而言,谷歌Gemini在模型规模、训练数据、优化策略等方面,Gemini都表现出了领先的优势,这无疑带来了压力和挑战。与此同时,国内的百度、腾讯、阿里等大厂也在积极投入大模型的研究和开发,并持续在底层技术上进行创新。
然而,在大模型的角力中,单纯的技术优势并不足以保证在大模型领域的长期领先,大模型的产业实践,也决定了大模型所能影响的广度。例如OpenAI即将在明年年初上线的GPT商店,便是扩展生态,探索多领域专业大模型落地的重要一步。与此同时,国内的百度、腾讯、阿里等大厂也在积极投入大模型的研究和开发,推出了各自的大模型产品,并持续在底层技术上进行创新。
而纵观整个大模型格局,国内大模型的研发和应用仍然需要长期且持续的中文语料数据和行业数据的浇灌,同时在基础设施层面增强先进、有效的算力的开发。大模型之家坚信,随着未来越来越多优质大模型走进生成式AI的“深水区”,将推动各大厂商在技术研发和创新上的投入,技术上的角力,引领产业迎来良性发展的循环。
原创文章,作者:王昊达,如若转载,请注明出处:http://damoai.com.cn/archives/2469