
大模型之家讯(报道:王昊达)11 月 13 日,“数聚未来 —— 凤凰大模型数据研讨沙龙” 成功在京举行,凤凰卫视执行副总裁兼运营总裁李奇,微博COO、新浪移动 CEO、新浪AI媒体研究院院长王巍,华为EI产品部部长尤鹏,智谱AI副总裁刘佳,MiniMax副总编辑苏彤等多位行业代表出席本次论坛,共同探讨高质量数据构建与基于数据驱动的大模型训练优化。


期间,凤凰卫视正式推出“凤凰智媒AI数据业务”,并发布首批 “中文访谈对话数据集” 和 “正向价值对齐数据集”。凤凰数据的核心目标是推动AI数据领域华语数据的丰富与共享,同时为中华文化的传承与传播提供AI时代的探索思路和解决方案,让AI与中华文化认知对齐更简单。
数据产业的发展需要AI领域各方同仁共同参与
凤凰卫视执行副总裁兼运营总裁李奇在致辞中表示,数据仍然是目前人工智能发展的短板之一。数据就像是人工智能时代的石油资源,它的开发和应用都将是一个系统工程,需要产业界无数企业共同参与。凤凰卫视作为一个立足香港、背靠内地、面向全球发展的国际媒体,也将是人工智能时代的积极参与者,期望发挥凤凰的媒体平台优势,为产业界建立一个共建共享的数据平台,共同推进人工智能的快速发展。

微博COO、新浪移动CEO、新浪AI媒体研究院院长王巍在主旨演讲《数据赋能:微博探索AIGC多场景应用》中提出,围绕大模型,目前已经形成由基础设施层、模型层、应用层共同构成的AIGC生态体系。对于媒体而言,AIGC将带来内容生产方式的变革,AIGC 时代的内容质量、效率及产量都将迎来高速发展。在未来,AI将创造出一种新型的“人机共存消费模式”。

智谱AI副总裁刘佳带来《ChatGLM3: 模型、平台与应用》的主旨演讲。刘佳表示,随着 2020 年 ChatGPT 的问世,生成式 AI 步入 “第一阶段”。而在当前,市场已进入 “第二阶段”,生成式 AI 开始在千行百业落地。刘佳形容说,之前我们找到了锤子,现在我们要发现更多的钉子,让大模型的能力应用落地。
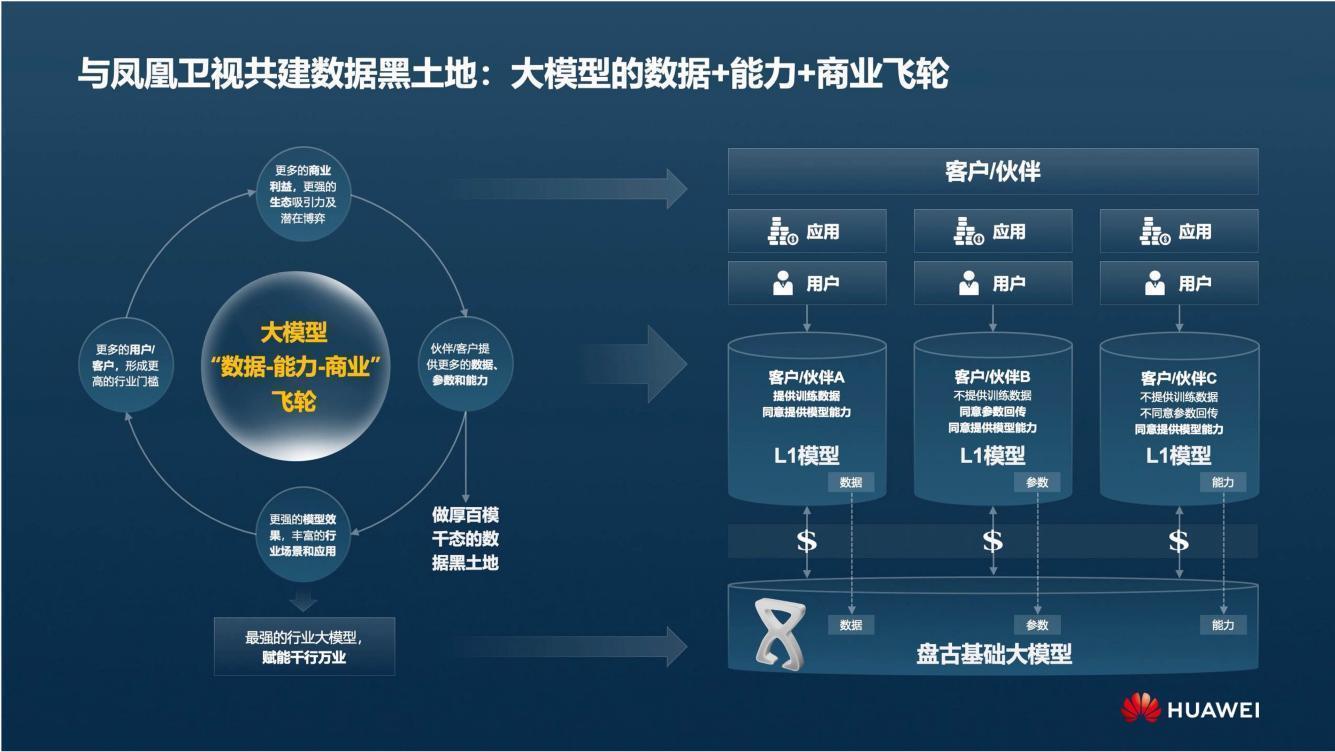
华为云EI产品部部长尤鹏带来《盘古大模型的数据之道》的主旨演讲。尤鹏表示,华为希望和凤凰卫视一起共建数据黑土地,共同探索产业界自下而上的数据合作路径和商业模式,共同构建大模型的“数据-算力-商业”飞轮,推动数据产业发展。
中国科学院信息工程研究所研究员张潇丹介绍了 “正向价值” 对于大模型的重要性。她表示,虽然大模型正处在蓬勃发展的时代,但也存在诸多风险因素,比如虚假信息的生成、语言偏见等,这些风险源自于训练数据的偏颇、模型自身逻辑缺陷及缺乏纠错能力等,因此亟需建立大模型的正向价值体系。
MiniMax 副总编辑苏彤分享了《大模型应用落地与安全管理探索》的主旨演讲。百度、京东、蚂蚁、360、知乎、旷视、中科闻歌、蜜度、面壁智能等业界厂商代表也出席了此次论坛活动。
行业专家共同探讨大模型未来挑战与机会
除主旨演讲外,香港科技大学 (广州) 协理副校长熊辉,视觉中国创始人、总裁柴继军,商汤科技数字文娱总经理栾青,中科闻歌创始合伙人兼 CTO 曹家参加了《“与未来对话” 大模型下一阶段的落点挑战与机会》圆桌论坛,各位来宾就自身领域发表了精彩见解,磐霖资本风险合伙人、独到科技联合创始⼈兼CTO陈利人担任主持人。

香港科技大学 (广州) 协理副校长熊辉指出,虽然算力是行业公认的中国大模型面临的挑战之一,但在他看来,真正的挑战是数据。虽然国内大模型在中文数据上占有优势,但整体的中文数据在整个人类知识的数据体系中仅占很小一部分,中国大模型如何能够真正做到跨语言体系、跨文化体系,构建起高价值、高质量、全方位的数据集,仍然面临较大挑战。

视觉中国创始人、总裁柴继军表示,AIGC 将会对传统的版权生态形成极大挑战。在他看来,人类创作与机器创作能否真正做到人机协同尚无明确答案,如何更好地保护版权,让内容源头的创作者分享人工智能再创作的价值,也仍然充满挑战。

商汤科技数字文娱总经理栾青指出,当前市场对于大模型的未来发展及应用暂时处在探索阶段,需要各方力量共同努力。作为发展大模型公司之一的商汤科技,她表示,凤凰卫视此次推出的数据平台令人振奋,期望行业中有更多的媒体、企业能参与其中,推出更多具备结构化、更丰富的数据资源。

中科闻歌创始合伙人兼 CTO 曹家认为,我们需要正视本土大模型与国外以 OpenAI 为首的大模型产品的差距,但本土大模型在中文能力仍具有一定优势。他表示,大模型的训练数据首先规模要足够大,其次需要平衡数据之间的内容配比,同时要保证数据的高质量,清洗掉数据中的冗余、劣质信息。

凤凰数据:为 AI 时代中华文化传播提供支撑
作为本次大模型数据研讨沙龙的重磅环节,凤凰卫视正式推出旗下面向AI时代的全新业务 ——“凤凰智媒AI数据业务”,并发布首批 “中文访谈对话数据集” 和 “正向价值对齐数据集”。
凤凰卫视融媒体研发副总经理冯伟表示,高质量的数据语料库是AI时代承载中华文化的新载体,凤凰数据的核心目标是为AI时代的中华文化传播奠定坚实基础,让AI与中华文化认知对齐更简单。

其中,“中文访谈对话数据集” 基于凤凰卫视访谈类节目生成,规模达百万轮次,连续对话的平均轮次超 30 轮次。“正向价值对齐数据集” 的构建则以权威学术团队的研究成果为指导,由凤凰卫视专业内容团队人工撰写而成,规模达十万个问答对。
除上述两个数据集外,凤凰数据还有多个数据集正在加工生成中,包括面向财经领域的评论数据集、面向视频内容理解领域的视频问答数据集、面向数字人领域的谈话动作数据集和语音合成数据集等。同时,凤凰数据也在同相关数据伙伴共同构建具有高价值和稀缺性的高质量数据集,包括华语图文对数据集、华语书籍数据集和网络流行语数据集。
除了高质量数据集产品外,凤凰数据还将推出以数据为中心的一站式AI训练平台,计划于近期开放内测。平台将与高质量数据集市实现互联互通,确保数据在平台内的安全使用。平台也将提供一系列以数据为中心的服务,包括丰富的数据处理工具、可视化模型训练和微调套件、全面的数据和模型评估框架和多云异构的算力资源。

据悉,2024 年,凤凰数据计划分三批发布更多高质量数据集,并正式上线AI训练平台。同时,凤凰数据还将举行 “Link + 科技峰会” 和 “AI数据挑战赛” 等系列活动,连接各界,解决行业痛点,共同推进AI与华语文化的认知进程。
面向高校及科研院所,凤凰卫视发布了 “凤凰智媒AI筑巢计划”,提供部分数据集的免费授权,以助力学术研究和创新。凤凰AI数据官网于发布会当天正式上线,为行业客户提供数据集试用下载服务。
原创文章,作者:王昊达,如若转载,请注明出处:http://damoai.com.cn/archives/1842