
大模型之家讯 7月23日,昆仑万维发布其最新一代音乐生成模型 Mureka V7 及首个支持 Voice Design 的音频模型 Mureka TTS V1,意图在全球音频内容创作领域进一步推进AI工具的可用性和专业化。这一版本的发布,不仅提升了模型输出的音乐与语音质量,还展示了AI在“音乐性”与“表达力”方面的最新进展。
Mureka V7:音乐生成效率与品质的双重跃迁
昆仑万维将Mureka V7定位为“全天候的私人录音棚”。相比传统音乐创作流程,Mureka V7将歌词输入与风格选择缩减为单次点击操作,仅用数分钟即可输出完整曲目。这种流程极大降低了音乐生产门槛,同时也在作品质量上实现显著提升。
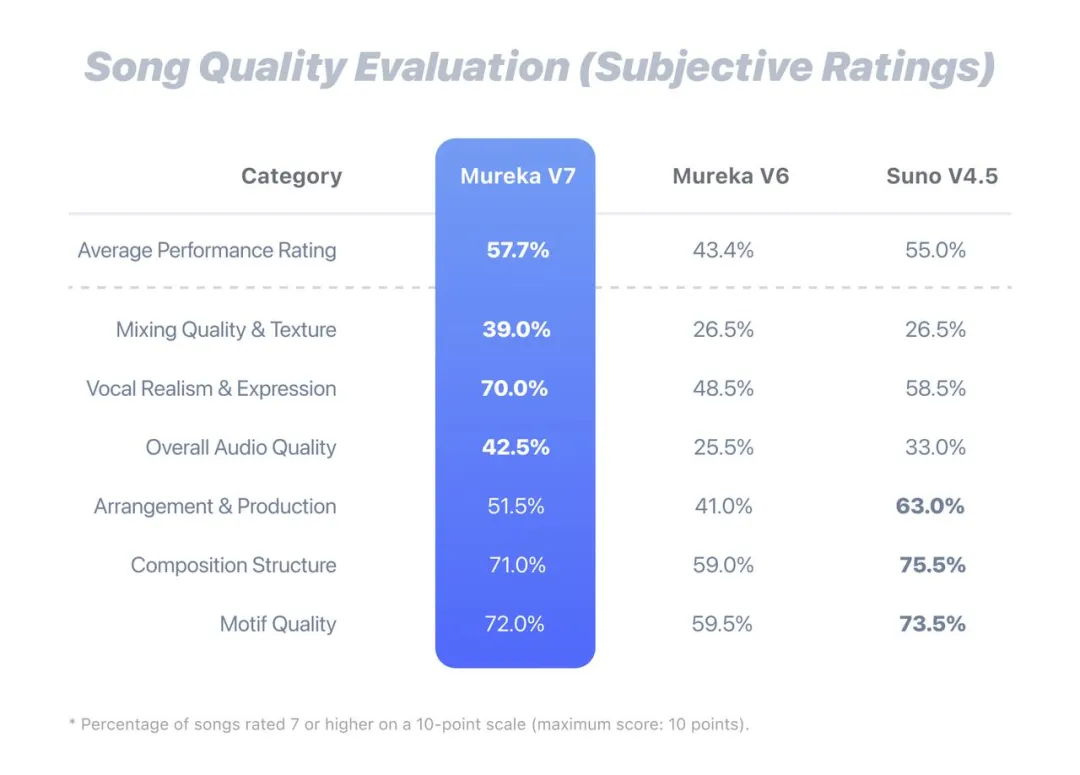

根据官方提供的数据,Mureka V7在旋律动机、编曲质量以及人声与乐器真实度等维度均实现显著优化。生成作品的“良品率”从前一版本的43.4%提升至57.7%,人声真实度与表现力提高44%,整体音质提升近一倍。
技术层面,这一代模型基于对MusiCoT(MusiCoT: Analyzable Chain-of-Musical-Thought Prompting)技术的进一步迭代。该技术通过在音频生成前引导模型完成结构性规划,使生成内容更具连贯性与艺术表现力。与传统自回归音乐生成模型不同,MusiCoT强调“先整体规划、后局部填充”的创作逻辑,以此更贴近人类音乐创作的思维过程。
此外,MusiCoT还集成了CLAP(对比式语言-音频预训练模型),使得模型能在参考已有音频风格的基础上,进行可解释且具有风格适配性的创作,而非单纯复制已有作品。
从多项主观与客观评价指标来看,Mureka V7在旋律连贯性、段落推进、情绪控制等方面均达到业内领先水准,体现出其在音乐生成结构性与创新性上的系统性升级。
Mureka TTS V1:从克隆到设计的音色定制
此次发布的另一款产品Mureka TTS V1,提供了完整的“音色设计(Voice Design)”能力。该功能允许用户通过文本指令设定声音特征,实现从音色生成到个性化定制的全流程控制。相比传统语音合成依赖现有音色库的方式,这种方法具备更高的灵活性与创造空间。
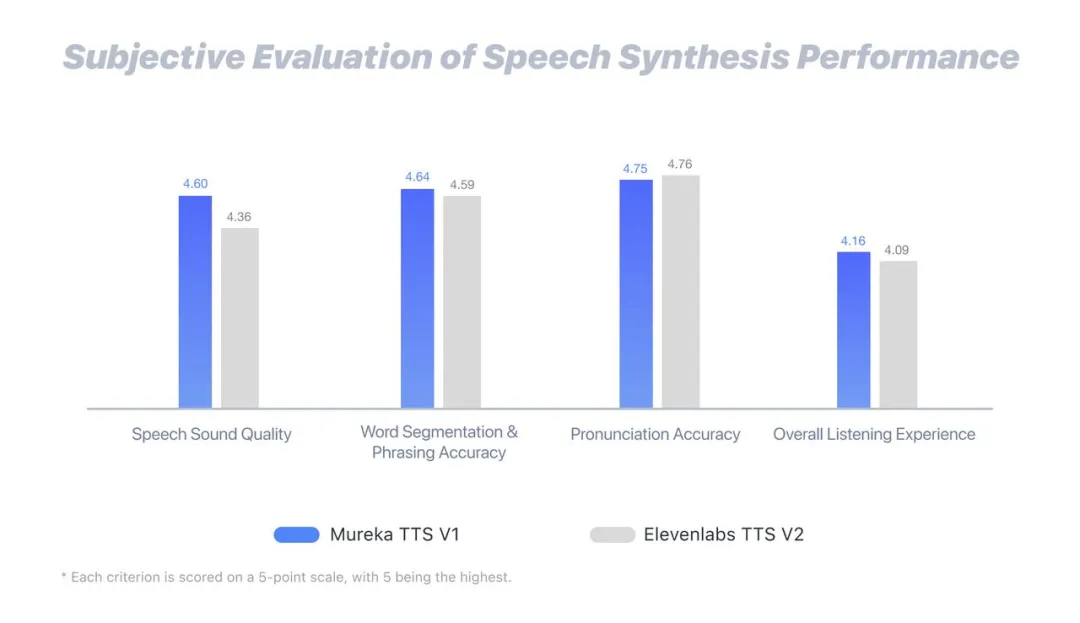
在语音质量指标方面,Mureka TTS V1得分达4.6分,超过ElevenLabs等同类产品。文字切分与段落理解方面评分为4.64,显示其在语言理解层面也具备较高水准。
通过具体示例展示,该模型可以生成从史诗电影旁白到动画角色语音、从企业宣传配音到奇幻角色台词等多种风格,体现出其声音生成系统的广泛适配性和表达自由度。
AI生成音乐的技术跃进与社会意义
Mureka V7和TTS V1的推出,是AI从“功能性工具”向“创意共创者”角色转变的一个显性信号。在生成音乐与语音方面,AI不再仅仅作为加速内容生产的手段,而是逐步渗透进情感表达与叙事构建的过程。此类模型技术的迭代背后,代表着算法与人类创作逻辑的深度融合,也提出了新的创作伦理和审美判断命题。
在全球内容生产正在加速“个体化”与“平台化”并存的背景下,AI生成技术正重塑创作者与听众之间的关系。这种变化不仅体现在效率提升,更体现在音乐、声音所承载的文化张力与情感共鸣上。随着Mureka系列工具进入更多创作场景,其对音乐产业链、语音内容生成以及虚拟人等多个领域的推动作用值得持续观察。
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/11624