
大模型之家讯 2024年首份大模型报告来了!近日发布的《大语言模型能力测评报告2024》通过3000多道测试题,对国内外主流的10个大语言模型进行了评测,结果显示大模型行业也存在“马太效应”:一直处于领先地位的文心一言和ChatGPT继续领跑中美大模型,且优势愈发明显,进一步拉开了与其他大模型的差距。
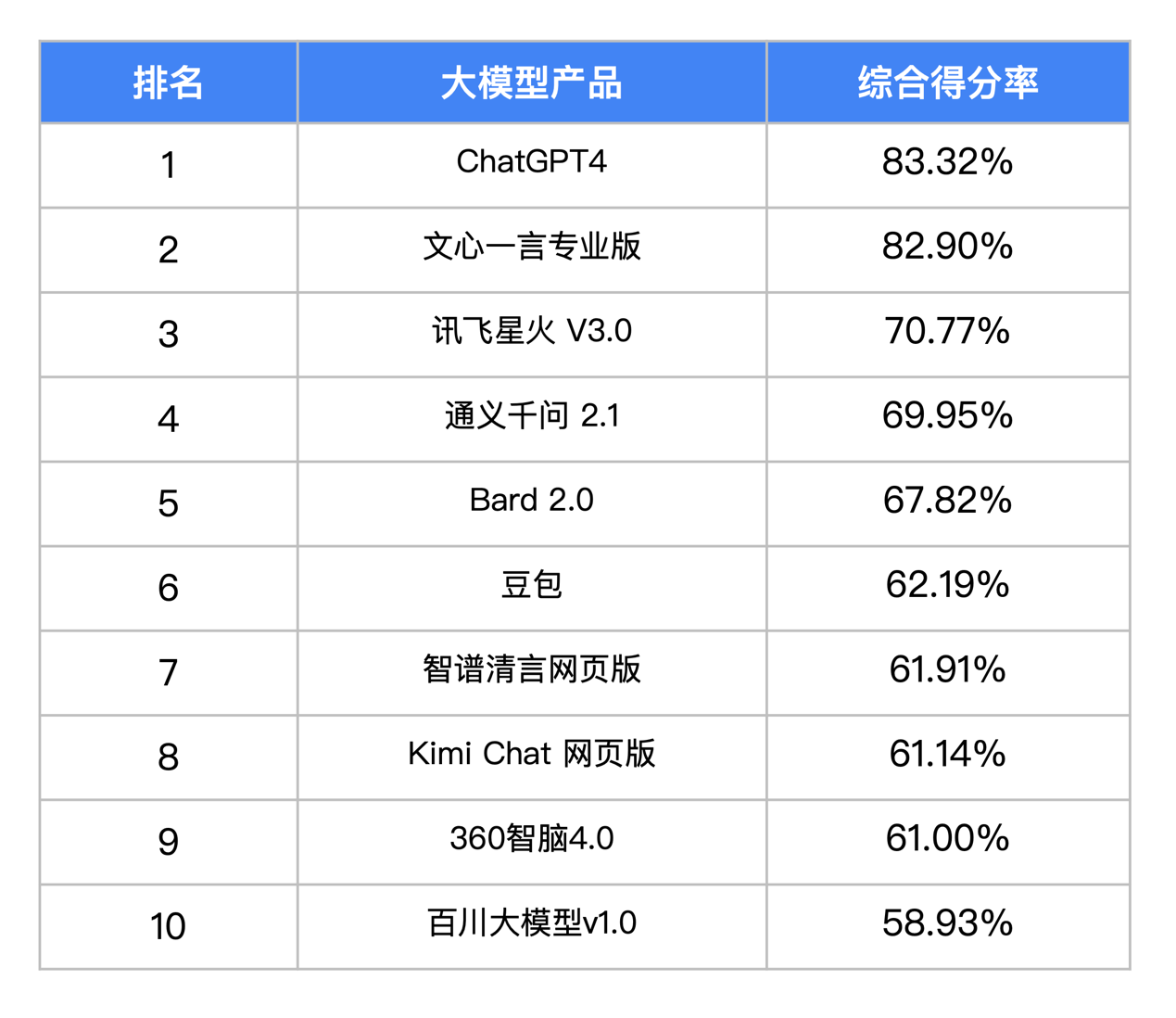
报告显示,GPT-4以83.32%的综合得分率位居第一,百度文心一言紧随其后。文心一言82.9%的得分率与 ChatGPT 得分非常接近,仅仅相差 0.42%。大模型狂奔一年之后,国内大模型产品格局已经初步形成,头部企业呈现了领先态势。

2023 年下半年,国内的大型模型已经进入了一个显著的成长阶段。不仅模型的数量呈现出爆炸式的增长趋势,而且模型的质量也在持续提升。
报告指出,在众多国产大模型中,文心一言的综合表现突出,不仅在中文语义理解、逻辑推理、代码编写、知识问答等基础能力上领先,更在多模态处理等方面树立了国产大语言模型的新标杆。具体来看,在编程能力、逻辑能力、上下文能力、翻译能力、文学写作能力等9项评测维度中,文心一言拿下了其中的6项第一,在所有评测模型中处于绝对领先。
截至2023年12月31日,已有两批超过20个大模型获得相关备案批准,面向公众开放。越来越多的国产大模型正进入用户的视野和认知中。
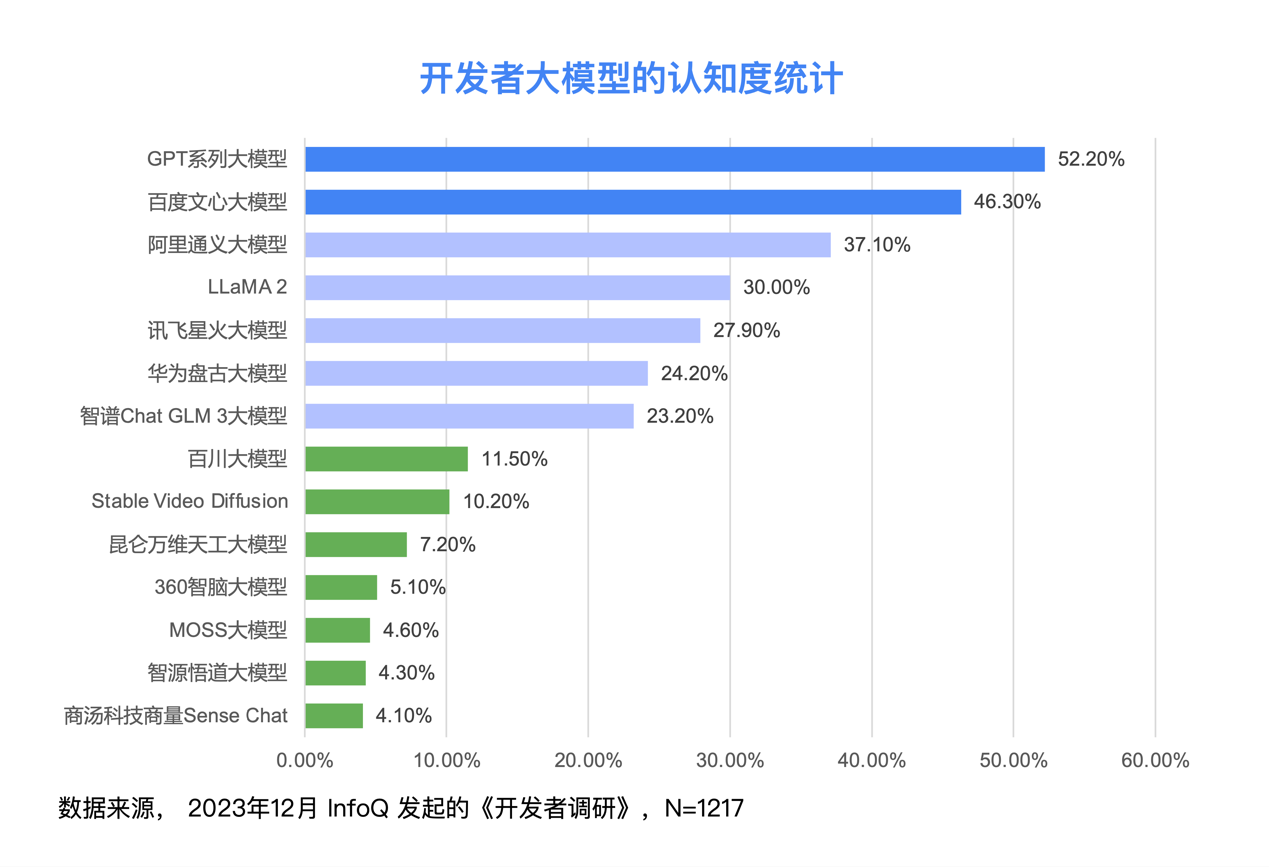
最新统计数据显示,在目前的市场上,GPT 系列大模型和百度文心大模型已经稳居第一梯队,受到了广泛的关注和应用。近半数的受访开发者表示,他们了解或使用过这两款模型,充分证明两者在行业内的领先地位和影响力。
公开资料也显示,百度文心一言用户规模已突破1亿,自2023年8月31日率先获准开放对公众提供服务以来,文心一言的用户提问量一路上扬,越来越多的用户在信任和使用文心一言。
报告认为,未来大模型产品有望诞生新的超级应用,企业级需求落地将成为2024年重要的行业⻛向。无论个人用户市场,还是企业级市场,大模型产品的落地都需要强大的基础大模型,将为AI原生应用的爆发提供驱动。百度文心大模型4.0、GPT-4等领先的大模型或将成为越来越多用户和企业的首选,进行AI原生应用的开发和场景落地。
原创文章,作者:志斌,如若转载,请注明出处:http://damoai.com.cn/archives/3274